Ceph Storage Erasure Code FAQ
Recently, a customer asked several questions about how Ceph storage utilizes Erasure Code to protect data, avoid data corruption in the event of hardware failure, data recovery time, how to choose K+M, and the minimum number of servers required for Ceph. We believe that many IT professionals familiar with traditional storage systems will be interested in understanding the features of the new generation of software-defined storage. I will share with you several questions that customers often ask in this article.
How long will Ceph take to recover from a Ceph disk failure?
The time required for recovering data from a storage device failure depends on the following conditions:
- The time for recovering the data is not related to the size of the hard disk. The time is proportional to the amount of data stored on the disk. Ceph only needs to restore the damaged data. The less data damaged, the faster the repair. Ceph does not rebuild a disk like the RAID controller.
- Ceph re-heals the data to the healthy disks in the cluster. The more disks and hosts in the cluster, the faster the recovery
- The recovery speed can be adjusted by software parameters. The higher the recovery speed is set, the faster the recovery. Accelerating the recovery will occupy more CPU and network hardware resources.
- CPU performance and network bandwidth will also affect the recovery speed.
- The recovery speed of a replicated pool will be faster than the erasure code pool.
- Generally, administrators can slow down the recovery speed to reduce the use of server resources.
Reference time for recovery:
- NVMe SSD could take a few hours.
- HDD could take about one day
How to choose the Erasure Code K & M numbers?
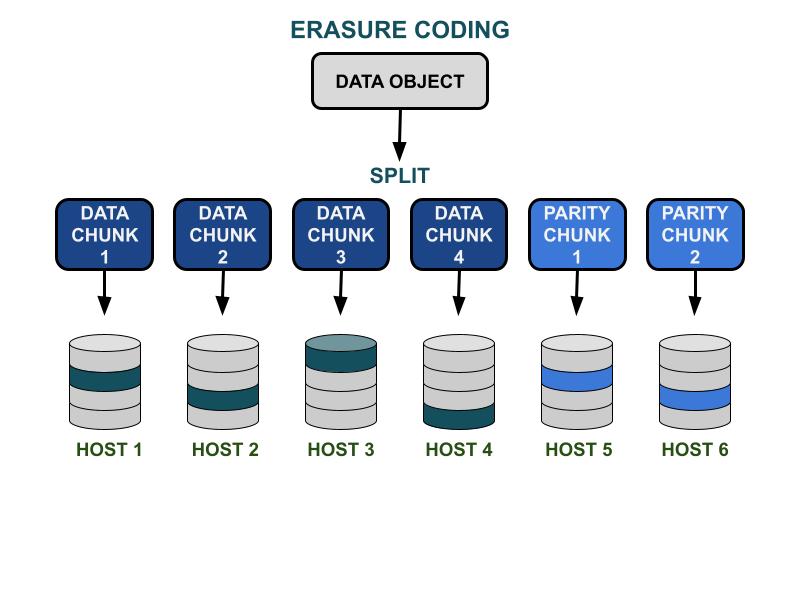
How erasure code works
The Ceph erasure code parameters K & M involve the usable capacity efficiency and redundancy against hardware failure. K is the number of data chunks, and M is the number of coding chunks. When a client writes a data object to the Ceph storage cluster, the data object will be split into K equal-sized data chunks. Ceph uses the data chunks to encode M chunks of coding chunks, which will be used to calculate the lost data chunks when hardware fails. Data chunks and coding chunks will be distributed and stored in the K+M specified failure domain. The maximum number of data chunks that can be lost is M failure domains. The available failure domains depend on how the storage servers are allocated within the physical infrastructure. For a small-scale Ceph cluster, failure could be on disk or server hosts. A larger-scale cluster’s failure domain can include server racks, server rooms, or data centers, among others. The data object is reconstructed from the data chunks when the client wants to read the data.
Storage performance
Compared to the Ceph data replication algorithm, erasure coding usually has better usable space efficiency. Because the erasure code utilizes more disk I/O operations to complete the data I/O, it is less friendly to the IOPS-demanding workloads. The larger the sum of K and M, the more I/O operations will consume disk IOPS resources. When using bigger K and smaller M, the total number of bytes of data transferred on the Ceph cluster network will be less. This could increase the I/O throughput performance of large-sized data objects.
Space efficiency
The usable space efficiency of an erasure code pool is equal to K/(K+M). For example, the space efficiency of the
K=4, M=2 erasure code pool is 4/6 = 66.7%. This is twice as efficient as replica 3 pools, which provide higher IOPS
performance with the same level of hardware redundancy.
Reasonable K is larger than M due to the usable space
efficiency. The larger (K-M) erasure code gains better space efficiency.
Number of server hosts
The number of K+M also determines the number of hosts or larger failure domains that are required in the cluster.
- A standard erasure code pool requires at least K + M server hosts to effectively distribute all EC chunks.
- An advanced erasure code configuration allows storing multiple EC chunks per failure domain. This configuration reduces the required number of servers for distributing EC chunks.
Summary of erasure code K & M influences:
- M determines the redundant number of failure domains.
- A larger K + M results in reduced small object IOPS performance for clients but improves throughput for larger objects.
- Storage space efficiency = K/(K+M)
- Minimum number of servers required.
What is the minimum number of Ceph OSD hosts needed to use the erasure code pool?
The best practice of using Ceph storage is to set the pool failure domain larger than the “host”. A data pool using a host as the failure domain instructs Ceph to write chunks distributedly to different hosts for ensuring data can be recovered for other chunks saved on other healthy hosts. Users can still configure the failure domain to “disk drive,” which protects data specifically against disk failures, similar to traditional disk arrays.
Here are the recommendations for the minimum number of hosts required to use an erasure code pool.
Best configuration: Number of servers ≧ K + M +1
- This configuration enables Ceph to distribute every EC chunk across K+M hosts.
- When one of the hosts fails, you have enough hosts to restore the lost chunk.
Second best configuration: Number of servers = K + M
- This configuration allows each EC chunk to be distributed across K+M hosts.
- When a host fails, you have no other host to restore the lost EC chunk. It is crucial to repair it promptly to restore the system to a healthy state as quickly as possible.
Budget-limited configuration: Number of servers ≧ (K + M) / M
This configuration instructs Ceph
to distribute several erasure-coded chunks across the designated number of hosts. When a host fails, at most M
chunks of an object will be lost.
This configuration allows
- Any number of disks can fail simultaneously in one host.
- Or the cluster can lose at most one host.
- Or only one disk in each of the M hosts can fail simultaneously.
For the example of K+M = 4+2, the minimum number of hosts required is 6/2 = 3. You can lose only one host, but you won't have enough healthy hosts in the cluster to re-heal the lost chunks.
How to calculate the usable capacity of a Ceph cluster?
The usable space in Ceph depends on several important factors.
1. The maximum raw capacity of a Ceph cluster constructed by multiple servers is the sum of the disk space in each
server.
If the cluster includes various types of storage devices, such as HDDs, SSDs, or NVMe drives, you should
calculate the total raw disk space for each device type separately. Ceph is capable of recognizing the designated
device class used by each pool.
2. The data protection applied to each Ceph pool determines the usable space.
- Replicated protection: usable space = raw capacity/replica size
- Erasure Code data protection: usable space = raw capacity x (K/(K+M))
3. Ceph has some overhead for metadata and system operations. The overhead space used is around 10 to 20% depending on your specific configuration and usage.
All disk drive space is shared among all replicated and erasure code pools
- Pools can set or not set quotas. All quotas are thin provisioning
- Because Ceph's available space is thin provisioning, storage space is allocated only when needed, rather than allocating all required space in advance. This can improve storage utilization and reduce storage costs.
- It is recommended to reserve 1/n space during operation as data recovery space in case of hardware failure, where n is the number of servers.
- The system has preset usage warnings of 85% near-full and 95% full.