Ceph 스토리지 이레이저 코드 FAQ
최근에 한 고객이 Ceph 스토리지가 데이터 보호를 위해 Erasure Code를 어떻게 활용하는지, 하드웨어 장애 발생 시 데이터 손상을 방지하는 방법, 데이터 복구 시간, K+M 선택 방법, 그리고 Ceph에 필요한 최소 서버 수에 대해 여러 가지 질문을 했습니다. 우리는 전통적인 스토리지 시스템에 익숙한 많은 IT 전문가들이 소프트웨어 정의 스토리지의 새로운 세대 기능을 이해하는 데 관심을 가질 것이라고 믿습니다. 이 기사에서는 고객들이 자주 묻는 여러 질문을 공유하겠습니다.
Ceph 디스크 장애에서 복구하는 데 얼마나 걸릴까요?
저장 장치 장애에서 데이터를 복구하는 데 필요한 시간은 다음 조건에 따라 다릅니다:
- 데이터 복구 시간은 하드 디스크의 크기와 관련이 없습니다. 시간은 디스크에 저장된 데이터 양에 비례합니다. Ceph는 손상된 데이터만 복구하면 됩니다. 손상된 데이터가 적을수록 복구가 더 빠릅니다. Ceph는 RAID 컨트롤러처럼 디스크를 재구성하지 않습니다.
- Ceph는 클러스터의 건강한 디스크로 데이터를 재복구합니다. 클러스터에 디스크와 호스트가 많을수록 복구 속도가 빨라집니다.
- 복구 속도는 소프트웨어 매개변수로 조정할 수 있습니다. 복구 속도가 높게 설정될수록 복구가 더 빨라집니다. 복구를 가속화하면 더 많은 CPU 및 네트워크 하드웨어 리소스를 차지하게 됩니다.
- CPU 성능과 네트워크 대역폭도 복구 속도에 영향을 미칩니다.
- 복제 풀의 복구 속도는 지우기 코드 풀보다 빠릅니다.
- 일반적으로 관리자는 서버 리소스 사용을 줄이기 위해 복구 속도를 늦출 수 있습니다.
복구를 위한 참조 시간:
- NVMe SSD는 몇 시간이 걸릴 수 있습니다.
- HDD는 약 하루가 걸릴 수 있습니다.
지우기 코드 K 및 M 숫자를 선택하는 방법은?
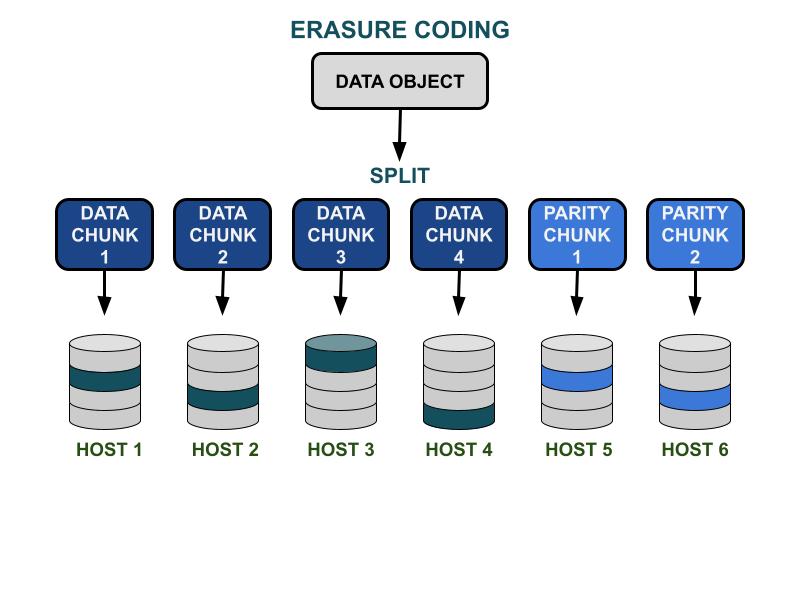
지우기 코드 작동 방식
Ceph 지우기 코드 매개변수 K & M은 사용 가능한 용량 효율성과 하드웨어 고장에 대한 중복성을 포함합니다. K는 데이터 청크의 수이고, M은 코딩 청크의 수입니다. 클라이언트가 Ceph 스토리지 클러스터에 데이터 객체를 작성할 때, 데이터 객체는 K개의 동일한 크기의 데이터 청크로 분할됩니다. Ceph는 데이터 청크를 사용하여 M개의 코딩 청크를 인코딩하며, 이는 하드웨어가 실패할 때 손실된 데이터 청크를 계산하는 데 사용됩니다. 데이터 청크와 코드 청크는 K+M에서 지정한 실패 도메인에 분배되고 저장됩니다. 손실될 수 있는 데이터 청크의 최대 수는 M 실패 도메인입니다. 사용 가능한 실패 도메인은 물리적 인프라 내에서 스토리지 서버가 어떻게 할당되는지에 따라 달라집니다. 소규모 Ceph 클러스터의 경우, 실패는 디스크나 서버 호스트에서 발생할 수 있습니다. 대규모 클러스터의 실패 도메인에는 서버 랙, 서버실 또는 데이터 센터 등이 포함될 수 있습니다. 클라이언트가 데이터를 읽고자 할 때 데이터 청크에서 데이터 객체가 재구성됩니다.
저장 성능
Ceph 데이터 복제 알고리즘에 비해, 지우기 코딩은 일반적으로 더 나은 사용 가능한 공간 효율성을 가지고 있습니다. 지우기 코드는 데이터 I/O를 완료하기 위해 더 많은 디스크 I/O 작업을 사용하므로 IOPS를 요구하는 작업에 덜 친숙합니다. K와 M의 합이 클수록 I/O 작업이 디스크 IOPS 리소스를 더 많이 소모합니다. 더 큰 K와 더 작은 M을 사용할 때, Ceph 클러스터 네트워크에서 전송되는 데이터의 총 바이트 수는 줄어들 것입니다. 이것은 대용량 데이터 객체의 I/O 처리 성능을 향상시킬 수 있습니다.
공간 효율성
소거 코드 풀의 사용 가능한 공간 효율성은 K/(K+M)과 같습니다.예를 들어, K=4, M=2 소거 코드 풀의 공간 효율성은 4/6 = 66.7%입니다.이는 동일한 수준의 하드웨어 중복성을 가진 복제 3 풀보다 두 배 더 효율적입니다.
합리적인 K는 사용 가능한 공간 효율성으로 인해 M보다 큽니다.더 큰 (K-M) 삭제 코드는 더 나은 공간 효율성을 얻습니다.
서버 호스트 수
K+M의 수는 클러스터에서 필요한 호스트 또는 더 큰 장애 도메인의 수를 결정합니다.
- 표준 에러 정정 코드 풀은 모든 EC 청크를 효과적으로 분배하기 위해 최소 K + M 서버 호스트가 필요합니다.
- 고급 에러 정정 코드 구성은 장애 도메인당 여러 EC 청크를 저장할 수 있게 합니다. 이 구성은 EC 청크를 분배하는 데 필요한 서버 수를 줄입니다.
에러 정정 코드 K & M 영향 요약:
- M은 중복 장애 도메인의 수를 결정합니다.
- 더 큰 K + M은 클라이언트의 작은 객체 IOPS 성능을 감소시키지만 큰 객체의 처리량을 향상시킵니다.
- 저장 공간 효율성 = K/(K+M)
- 필요한 최소 서버 수.
에러 정정 코드 풀을 사용하기 위해 필요한 최소 Ceph OSD 호스트 수는 얼마입니까?
Ceph 스토리지를 사용하는 최선의 방법은 풀 실패 도메인을 "호스트"보다 크게 설정하는 것입니다. 호스트를 실패 도메인으로 사용하는 데이터 풀은 Ceph에 다른 호스트에 분산하여 청크를 기록하도록 지시하여 다른 건강한 호스트에 저장된 다른 청크의 데이터 복구를 보장합니다. 사용자는 여전히 실패 도메인을 "디스크 드라이브"로 구성할 수 있으며, 이는 전통적인 디스크 배열과 유사하게 디스크 고장에 대해 데이터를 보호합니다.
여기 에러 정정 코드 풀을 사용하기 위해 필요한 최소 호스트 수에 대한 권장 사항이 있습니다.
최고의 구성: 서버 수 ≧ K + M + 1
- 이 구성은 Ceph가 모든 EC 청크를 K+M 호스트에 분산할 수 있도록 합니다.
- 호스트 중 하나가 실패하면, 손실된 청크를 복구할 수 있는 충분한 호스트가 있습니다.
두 번째로 좋은 구성: 서버 수 = K + M
- 이 구성은 각 EC 청크가 K+M 호스트에 분산될 수 있도록 합니다.
- 호스트가 실패하면 잃어버린 EC 청크를 복구할 다른 호스트가 없습니다. 시스템을 가능한 한 빨리 건강한 상태로 복원하기 위해 신속하게 수리하는 것이 중요합니다.
예산 제한 구성: 서버 수 ≧ (K + M) / M
이 구성은 Ceph에 지정된 수의 호스트에 여러 개의 에러 정정 청크를 분산하도록 지시합니다.호스트가 실패하면 최대 M개의 객체 조각이 손실됩니다.
이 구성은 허용합니다.
- 하나의 호스트에서 동시에 여러 개의 디스크가 실패할 수 있습니다.
- 또는 클러스터는 최대 하나의 호스트를 잃을 수 있습니다.
- 또는 M개의 호스트 각각에서 동시에 하나의 디스크만 실패할 수 있습니다.
K+M = 4+2의 예에서 필요한 최소 호스트 수는 6/2 = 3입니다. 하나의 호스트만 잃을 수 있지만, 잃어버린 청크를 재복구할 만큼 건강한 호스트가 클러스터에 충분하지 않습니다.
Ceph 클러스터의 사용 가능한 용량을 어떻게 계산합니까?
Ceph의 사용 가능한 공간은 여러 중요한 요소에 따라 달라집니다.
1.여러 서버로 구성된 Ceph 클러스터의 최대 원시 용량은 각 서버의 디스크 공간의 합계입니다.
클러스터에 HDD, SSD 또는 NVMe 드라이브와 같은 다양한 유형의 저장 장치가 포함된 경우, 각 장치 유형에 대해 총 원시 디스크 공간을 별도로 계산해야 합니다.Ceph는 각 풀에서 사용되는 지정된 장치 클래스를 인식할 수 있습니다.
2. 각 Ceph 풀에 적용된 데이터 보호는 사용 가능한 공간을 결정합니다.
- 복제 보호: 사용 가능한 공간 = 원시 용량/복제 크기
- 소거 코드 데이터 보호: 사용 가능한 공간 = 원시 용량 x (K/(K+M))
3. Ceph는 메타데이터 및 시스템 작업에 대한 오버헤드가 있습니다. 사용되는 오버헤드 공간은 특정 구성 및 사용에 따라 약 10%에서 20%입니다.
모든 디스크 드라이브 공간은 모든 복제 및 소거 코드 풀 간에 공유됩니다.
- 풀은 쿼터를 설정하거나 설정하지 않을 수 있습니다. 모든 쿼터는 얇은 프로비저닝입니다.
- Ceph의 사용 가능한 공간이 얇은 프로비저닝이기 때문에, 필요한 경우에만 저장 공간이 할당되며, 모든 필요한 공간을 미리 할당하지 않습니다. 이는 저장소 활용도를 개선하고 저장 비용을 줄일 수 있습니다.
- 하드웨어 장애 발생 시 데이터 복구 공간으로 운영 중 1/n 공간을 예약하는 것이 권장됩니다. 여기서 n은 서버의 수입니다.
- 시스템은 85% 거의 가득 찬 상태와 95% 가득 찬 상태에 대한 사전 설정된 사용 경고가 있습니다.