Ceph Storage Erasure Code FAQ
Kürzlich stellte ein Kunde mehrere Fragen dazu, wie Ceph-Speicher Erasure Code nutzt, um Daten zu schützen, Datenkorruption im Falle eines Hardwareausfalls zu vermeiden, die Wiederherstellungszeit von Daten, wie man K+M auswählt und die minimale Anzahl an Servern, die für Ceph erforderlich ist. Wir glauben, dass viele IT-Profis, die mit traditionellen Speichersystemen vertraut sind, daran interessiert sein werden, die Funktionen der neuen Generation von softwaredefiniertem Speicher zu verstehen. Ich werde Ihnen in diesem Artikel mehrere Fragen mitteilen, die Kunden häufig stellen.
Wie lange wird Ceph benötigen, um sich von einem Ceph-Diskausfall zu erholen?
Die benötigte Zeit zur Wiederherstellung von Daten nach einem Ausfall des Speichermediums hängt von den folgenden Bedingungen ab:
- Die Zeit zur Wiederherstellung der Daten steht nicht im Zusammenhang mit der Größe der Festplatte. Die Zeit ist proportional zur Menge der auf der Festplatte gespeicherten Daten. Ceph muss nur die beschädigten Daten wiederherstellen. Je weniger Daten beschädigt sind, desto schneller erfolgt die Reparatur. Ceph baut eine Festplatte nicht wie der RAID-Controller wieder auf.
- Ceph stellt die Daten auf die gesunden Festplatten im Cluster wieder her. Je mehr Festplatten und Hosts im Cluster vorhanden sind, desto schneller erfolgt die Wiederherstellung.
- Die Wiederherstellungsgeschwindigkeit kann durch Softwareparameter angepasst werden. Je höher die Wiederherstellungsgeschwindigkeit eingestellt ist, desto schneller erfolgt die Wiederherstellung. Eine Beschleunigung der Wiederherstellung beansprucht mehr CPU- und Netzwerkressourcen.
- Die CPU-Leistung und die Netzwerkbandbreite beeinflussen ebenfalls die Wiederherstellungsgeschwindigkeit.
- Die Wiederherstellungsgeschwindigkeit eines replizierten Pools ist schneller als die eines Löschcode-Pools.
- Im Allgemeinen können Administratoren die Wiederherstellungsgeschwindigkeit verlangsamen, um den Einsatz von Serverressourcen zu reduzieren.
Referenzzeit für die Wiederherstellung:
- NVMe-SSD könnte einige Stunden in Anspruch nehmen.
- HDD könnte etwa einen Tag in Anspruch nehmen.
Wie wählt man die Erasure Code K & M Zahlen aus?
Wie der Löschcode funktioniert.
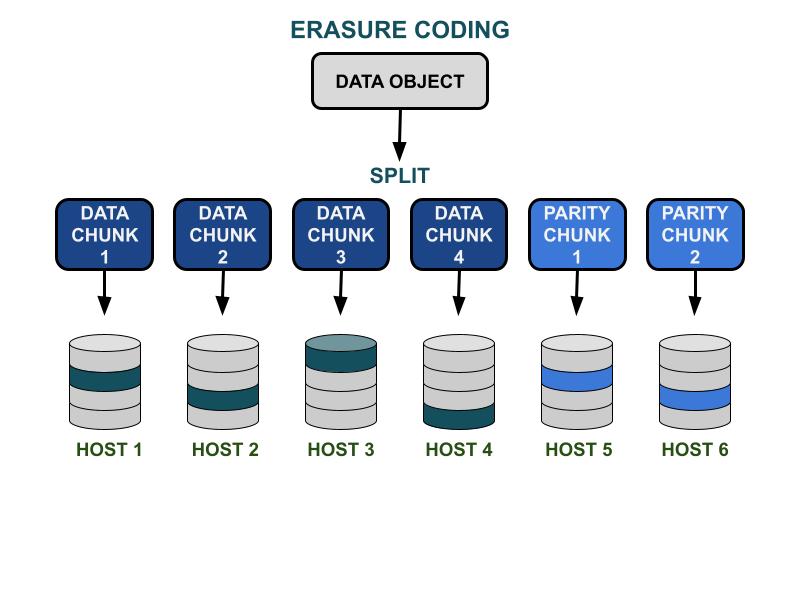
Die Ceph-Löschcode-Parameter K & M betreffen die nutzbare Kapazitätseffizienz und die Redundanz gegen Hardwareausfälle. K ist die Anzahl der Datenstücke, und M ist die Anzahl der Codierungsstücke. Wenn ein Client ein Datenobjekt in den Ceph-Speichercluster schreibt, wird das Datenobjekt in K gleich große Datenchunks aufgeteilt. Ceph verwendet die Datenstücke, um M Stücke von Codierungsstücken zu kodieren, die verwendet werden, um die verlorenen Datenstücke zu berechnen, wenn die Hardware ausfällt. Datenblöcke und Codeblöcke werden im von K+M angegebenen Fehlerbereich verteilt und gespeichert. Die maximale Anzahl an Datenfragmenten, die verloren gehen können, beträgt M Ausfallbereiche. Die verfügbaren Ausfallbereiche hängen davon ab, wie die Speicherserver innerhalb der physischen Infrastruktur zugewiesen sind. Bei einem kleinen Ceph-Cluster könnte der Fehler auf der Festplatte oder den Server-Hosts liegen. Der Ausfallbereich eines größeren Clusters kann unter anderem Server-Racks, Serverräume oder Rechenzentren umfassen. Das Datenobjekt wird aus den Datenfragmenten rekonstruiert, wenn der Client die Daten lesen möchte.
Speicherleistung
Im Vergleich zum Ceph-Datenreplikationsalgorithmus bietet Erasure Coding in der Regel eine bessere nutzbare Raumeffizienz. Da der Löschcode mehr Festplatten-I/O-Operationen benötigt, um die Daten-I/O abzuschließen, ist er weniger freundlich zu den IOPS-intensiven Arbeitslasten. Je größer die Summe von K und M ist, desto mehr I/O-Operationen werden die IOPS-Ressourcen der Festplatte verbrauchen. Bei der Verwendung von größeren K und kleineren M wird die Gesamtzahl der übertragenen Bytes im Ceph-Cluster-Netzwerk geringer sein. Dies könnte die I/O-Durchsatzleistung von großen Datenobjekten erhöhen.
Raumeffizienz
Die nutzbare Raumeffizienz eines Löschcode-Pools entspricht K/(K+M).Zum Beispiel beträgt die Raumeffizienz des K=4, M=2 Löschcodespeichers 4/6 = 66,7%.Dies ist doppelt so effizient wie Replica-3-Pools, die eine höhere IOPS-Leistung bei demselben Niveau an Hardware-Redundanz bieten.
Ein angemessenes K ist größer als M aufgrund der Effizienz des nutzbaren Speicherplatzes.Der größere (K-M) Löschcode erzielt eine bessere Raumeffizienz.
Anzahl der Server-Hosts
Die Anzahl der K+M bestimmt auch die Anzahl der Hosts oder größeren Ausfallbereiche, die im Cluster erforderlich sind.
- Ein standardmäßiger Löschcode-Pool benötigt mindestens K + M Server-Hosts, um alle EC-Chunks effektiv zu verteilen.
- Eine erweiterte Löschcode-Konfiguration ermöglicht das Speichern mehrerer EC-Chunks pro Ausfallbereich. Diese Konfiguration reduziert die erforderliche Anzahl von Servern zur Verteilung von EC-Chunks.
Zusammenfassung der Einflüsse von Löschcode K & M:
- M bestimmt die redundante Anzahl der Ausfallbereiche.
- Ein größeres K + M führt zu einer verringerten IOPS-Leistung für kleine Objekte bei Clients, verbessert jedoch den Durchsatz für größere Objekte.
- Speichereffizienz = K/(K+M)
- Mindestanzahl der erforderlichen Server.
Was ist die Mindestanzahl an Ceph OSD-Hosts, die benötigt wird, um den Löschcode-Pool zu verwenden?
Die beste Praxis bei der Verwendung von Ceph-Speicher besteht darin, die Fehlerdomäne des Pools größer als den "Host" zu setzen. Ein Datenpool, der einen Host als Fehlerdomäne verwendet, weist Ceph an, Datenstücke verteilt auf verschiedene Hosts zu schreiben, um sicherzustellen, dass Daten von anderen auf gesunden Hosts gespeicherten Datenstücken wiederhergestellt werden können. Benutzer können die Fehlerdomäne weiterhin auf "Festplattentreiber" konfigurieren, was Daten speziell gegen Festplattenausfälle schützt, ähnlich wie bei traditionellen Festplattenarrays.
Hier sind die Empfehlungen für die Mindestanzahl an Hosts, die erforderlich sind, um einen Löschcode-Pool zu verwenden.
Beste Konfiguration: Anzahl der Server ≧ K + M +1
- Diese Konfiguration ermöglicht es Ceph, jeden EC-Chunk über K+M Hosts zu verteilen.
- Wenn einer der Hosts ausfällt, haben Sie genügend Hosts, um den verlorenen Chunk wiederherzustellen.
Zweitbeste Konfiguration: Anzahl der Server = K + M
- Diese Konfiguration ermöglicht es, dass jeder EC-Chunk auf K+M Hosts verteilt wird.
- Wenn ein Host ausfällt, haben Sie keinen anderen Host, um den verlorenen EC-Chunk wiederherzustellen. Es ist entscheidend, ihn umgehend zu reparieren, um das System so schnell wie möglich wieder in einen gesunden Zustand zu versetzen.
Budgetbeschränkte Konfiguration: Anzahl der Server ≧ (K + M) / M
Diese Konfiguration weist Ceph an, mehrere fehlerkorrigierte Chunks auf die festgelegte Anzahl von Hosts zu verteilen.Wenn ein Host ausfällt, gehen höchstens M Teile eines Objekts verloren.
Diese Konfiguration ermöglicht
- Eine beliebige Anzahl von Festplatten kann gleichzeitig in einem Host ausfallen.
- Oder der Cluster kann höchstens einen Host verlieren.
- Oder nur eine Festplatte in jedem der M Hosts kann gleichzeitig ausfallen.
Für das Beispiel von K+M = 4+2 beträgt die minimale Anzahl an benötigten Hosts 6/2 = 3. Sie können nur einen Host verlieren, aber Sie haben nicht genügend gesunde Hosts im Cluster, um die verlorenen Chunks wiederherzustellen.
Wie berechnet man die nutzbare Kapazität eines Ceph-Clusters?
Der nutzbare Speicher in Ceph hängt von mehreren wichtigen Faktoren ab.
1.Die maximale Rohkapazität eines Ceph-Clusters, der aus mehreren Servern besteht, ist die Summe des Speicherplatzes in jedem Server.
Wenn der Cluster verschiedene Arten von Speichergeräten umfasst, wie HDDs, SSDs oder NVMe-Laufwerke, sollten Sie den gesamten Rohspeicherplatz für jeden Gerätetyp separat berechnen.Ceph ist in der Lage, die zugewiesene Geräteklasse zu erkennen, die von jedem Pool verwendet wird.
2. Der Datenschutz, der auf jeden Ceph-Pool angewendet wird, bestimmt den nutzbaren Speicher.
- Replikationsschutz: nutzbarer Speicher = Rohkapazität/Replikatgröße
- Erasure Code-Datenschutz: nutzbarer Speicher = Rohkapazität x (K/(K+M))
3. Ceph hat einen gewissen Overhead für Metadaten und Systemoperationen. Der verwendete Overhead-Speicher beträgt je nach spezifischer Konfiguration und Nutzung etwa 10 bis 20 %.
Der gesamte Speicherplatz der Festplatten wird unter allen replizierten und Erasure-Code-Pools geteilt.
- Pools können Quoten festlegen oder nicht festlegen. Alle Quoten sind Thin Provisioning.
- Da der verfügbare Speicherplatz von Ceph Thin Provisioning ist, wird Speicherplatz nur bei Bedarf zugewiesen, anstatt den gesamten benötigten Speicher im Voraus zuzuweisen. Dies kann die Speicherauslastung verbessern und die Speicherkosten senken.
- Es wird empfohlen, während des Betriebs 1/n Speicher als Datenwiederherstellungsraum im Falle eines Hardwareausfalls zu reservieren, wobei n die Anzahl der Server ist.
- Das System hat voreingestellte Nutzungshinweise von 85 % bei fast vollem und 95 % bei vollem Speicher.