Domande frequenti sul codice di cancellazione di Ceph Storage
Recentemente, un cliente ha posto diverse domande su come Ceph storage utilizza il Codice di Cancellazione per proteggere i dati, evitare la corruzione dei dati in caso di guasto hardware, il tempo di recupero dei dati, come scegliere K+M e il numero minimo di server richiesti per Ceph. Crediamo che molti professionisti IT familiari con i sistemi di archiviazione tradizionali saranno interessati a comprendere le caratteristiche della nuova generazione di archiviazione definita dal software. Condividerò con te diverse domande che i clienti pongono spesso in questo articolo.
Quanto tempo ci vorrà a Ceph per recuperare da un guasto del disco Ceph?
Il tempo necessario per recuperare i dati da un guasto del dispositivo di archiviazione dipende dalle seguenti condizioni:
- Il tempo per recuperare i dati non è correlato alla dimensione del disco rigido. Il tempo è proporzionale alla quantità di dati memorizzati sul disco. Ceph ha solo bisogno di ripristinare i dati danneggiati. Meno dati sono danneggiati, più veloce è la riparazione. Ceph non ricostruisce un disco come fa il controller RAID.
- Ceph ripristina i dati sui dischi sani nel cluster. Più dischi e host ci sono nel cluster, più veloce sarà il recupero.
- La velocità di recupero può essere regolata tramite parametri software. Maggiore è la velocità di recupero impostata, più veloce sarà il recupero. Accelerare il recupero occuperà più risorse hardware della CPU e della rete.
- Le prestazioni della CPU e la larghezza di banda della rete influenzeranno anche la velocità di recupero.
- La velocità di recupero di un pool replicato sarà più veloce rispetto a quella di un pool con codice di cancellazione.
- In generale, gli amministratori possono rallentare la velocità di recupero per ridurre l'uso delle risorse del server.
Tempo di riferimento per il recupero:
- Un SSD NVMe potrebbe richiedere alcune ore.
- Un HDD potrebbe richiedere circa un giorno.
Come scegliere i numeri K & M del codice di cancellazione?
Come funziona il codice di cancellazione.
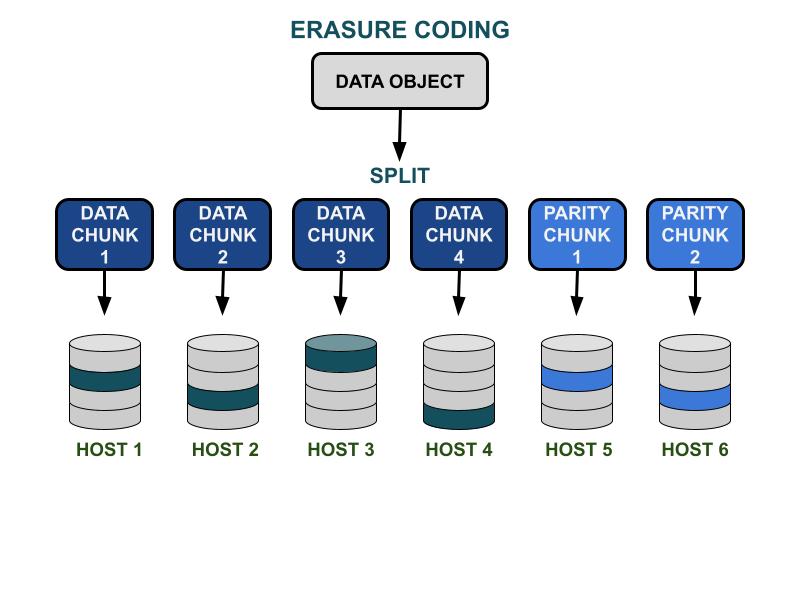
I parametri del codice di cancellazione Ceph K & M riguardano l'efficienza della capacità utilizzabile e la ridondanza contro i guasti hardware. K è il numero di chunk di dati e M è il numero di chunk di codifica. Quando un cliente scrive un oggetto dati nel cluster di archiviazione Ceph, l'oggetto dati verrà suddiviso in K chunk di dati di dimensioni uguali. Ceph utilizza i chunk di dati per codificare M chunk di chunk di codifica, che verranno utilizzati per calcolare i chunk di dati persi quando l'hardware fallisce. I blocchi di dati e i blocchi di codice saranno distribuiti e memorizzati nel dominio di errore specificato da K+M. Il numero massimo di blocchi di dati che possono andare persi è M domini di guasto. I domini di errore disponibili dipendono da come i server di archiviazione sono allocati all'interno dell'infrastruttura fisica. Per un cluster Ceph di piccole dimensioni, il guasto potrebbe essere su disco o sui server host. Il dominio di guasto di un cluster su larga scala può includere rack di server, sale server o centri dati, tra gli altri. L'oggetto dati viene ricostruito dai frammenti di dati quando il client desidera leggere i dati.
Prestazioni di archiviazione
Rispetto all'algoritmo di replicazione dei dati Ceph, la codifica per cancellazione di solito ha una migliore efficienza dello spazio utilizzabile. Poiché il codice di cancellazione utilizza più operazioni di I/O su disco per completare l'I/O dei dati, è meno adatto ai carichi di lavoro che richiedono elevate IOPS. Maggiore è la somma di K e M, maggiore sarà il consumo di operazioni I/O delle risorse IOPS del disco. Quando si utilizzano K più grandi e M più piccoli, il numero totale di byte di dati trasferiti sulla rete del cluster Ceph sarà minore. Questo potrebbe aumentare le prestazioni di throughput I/O di oggetti dati di grandi dimensioni.
Efficienza spaziale
L'efficienza dello spazio utilizzabile di un pool di codici di cancellazione è pari a K/(K+M).Ad esempio, l'efficienza spaziale del pool di codici di cancellazione K=4, M=2 è 4/6 = 66,7%.Questo è due volte più efficiente rispetto ai pool di replica 3, che offrono prestazioni IOPS superiori con lo stesso livello di ridondanza hardware.
K ragionevole è maggiore di M a causa dell'efficienza dello spazio utilizzabile.Il codice di cancellazione più grande (K-M) ottiene una migliore efficienza dello spazio.
Numero di host del server
Il numero di K+M determina anche il numero di host o domini di guasto più grandi richiesti nel cluster.
- Un pool di codici di cancellazione standard richiede almeno K + M host del server per distribuire efficacemente tutti i chunk EC.
- Una configurazione avanzata del codice di cancellazione consente di memorizzare più chunk EC per dominio di guasto. Questa configurazione riduce il numero di server richiesti per distribuire i chunk EC.
Riepilogo delle influenze del codice di cancellazione K & M:
- M determina il numero ridondante di domini di guasto.
- Un K + M più grande comporta una riduzione delle prestazioni IOPS per oggetti piccoli per i client, ma migliora il throughput per oggetti più grandi.
- Efficienza dello spazio di archiviazione = K/(K+M)
- Numero minimo di server richiesti.
Qual è il numero minimo di host Ceph OSD necessari per utilizzare il pool di codici di cancellazione?
La migliore pratica per utilizzare lo storage Ceph è impostare il dominio di guasto del pool più grande del "host". Un pool di dati che utilizza un host come dominio di guasto istruisce Ceph a scrivere i chunk in modo distribuito su diversi host per garantire che i dati possano essere recuperati da altri chunk salvati su altri host sani. Gli utenti possono comunque configurare il dominio di guasto su "disco", che protegge i dati specificamente contro i guasti del disco, simile ai tradizionali array di dischi.
Ecco le raccomandazioni per il numero minimo di host richiesti per utilizzare un pool di codici di cancellazione.
Migliore configurazione: Numero di server ≧ K + M +1
- Questa configurazione consente a Ceph di distribuire ogni chunk EC su K+M host.
- Quando uno degli host fallisce, hai abbastanza host per ripristinare il chunk perso.
Seconda migliore configurazione: Numero di server = K + M
- Questa configurazione consente a ciascun chunk EC di essere distribuito su K+M host.
- Quando un host fallisce, non hai altri host per ripristinare il chunk EC perso. È fondamentale ripararlo prontamente per ripristinare il sistema in uno stato sano il più rapidamente possibile.
Configurazione con budget limitato: Numero di server ≧ (K + M) / M
Questa configurazione istruisce Ceph a distribuire diversi chunk codificati per cancellazione tra il numero designato di host.Quando un host fallisce, al massimo M pezzi di un oggetto andranno persi.
Questa configurazione consente
- Qualsiasi numero di dischi può guastarsi simultaneamente in un host.
- Oppure il cluster può perdere al massimo un host.
- Oppure solo un disco in ciascuno dei M host può guastarsi simultaneamente.
Per l'esempio di K+M = 4+2, il numero minimo di host richiesti è 6/2 = 3. Puoi perdere solo un host, ma non avrai abbastanza host sani nel cluster per ripristinare i chunk persi.
Come calcolare la capacità utilizzabile di un cluster Ceph?
Lo spazio utilizzabile in Ceph dipende da diversi fattori importanti.
1.La capacità massima grezza di un cluster Ceph costruito da più server è la somma dello spazio su disco in ciascun server.
Se il cluster include vari tipi di dispositivi di archiviazione, come HDD, SSD o unità NVMe, è necessario calcolare lo spazio su disco grezzo totale per ciascun tipo di dispositivo separatamente.Ceph è in grado di riconoscere la classe di dispositivo designata utilizzata da ciascun pool.
2. La protezione dei dati applicata a ciascun pool Ceph determina lo spazio utilizzabile.
- Protezione replicata: spazio utilizzabile = capacità grezza/dimensione replica
- Protezione dei dati con Erasure Code: spazio utilizzabile = capacità grezza x (K/(K+M))
3. Ceph ha un certo overhead per i metadati e le operazioni di sistema. Lo spazio di overhead utilizzato è di circa il 10-20% a seconda della tua configurazione specifica e dell'uso.
Tutto lo spazio dei dischi è condiviso tra tutti i pool replicati e con Erasure Code
- I pool possono impostare o meno le quote. Tutte le quote sono thin provisioning
- Poiché lo spazio disponibile di Ceph è thin provisioning, lo spazio di archiviazione viene allocato solo quando necessario, piuttosto che allocare tutto lo spazio richiesto in anticipo. Questo può migliorare l'utilizzo dello storage e ridurre i costi di archiviazione.
- Si consiglia di riservare 1/n dello spazio durante l'operazione come spazio di recupero dati in caso di guasto hardware, dove n è il numero di server.
- Il sistema ha avvisi di utilizzo preimpostati dell'85% quasi pieno e del 95% pieno.