Často kladené otázky o kódování chyb v úložišti Ceph
Nedávno se zákazník ptal na několik otázek ohledně toho, jak Ceph storage využívá Erasure Code k ochraně dat, jak se vyhnout poškození dat v případě hardwarového selhání, čas na obnovu dat, jak vybrat K+M a minimální počet serverů potřebných pro Ceph. Věříme, že mnoho IT profesionálů obeznámených s tradičními úložnými systémy bude mít zájem porozumět vlastnostem nové generace softwarově definovaného úložiště. V tomto článku se s vámi podělím o několik otázek, které zákazníci často kladou.
Jak dlouho potrvá, než se Ceph zotaví z poruchy disku Ceph?
Doba potřebná k obnovení dat z poruchy úložného zařízení závisí na následujících podmínkách:
- Čas potřebný k obnovení dat není závislý na velikosti pevného disku. Čas je úměrný množství dat uložených na disku. Ceph potřebuje pouze obnovit poškozená data. Čím méně dat je poškozeno, tím rychlejší je oprava. Ceph neobnovuje disk jako řadič RAID.
- Ceph znovu obnovuje data na zdravé disky v clusteru. Čím více disků a hostitelů je v clusteru, tím rychlejší je obnova.
- Rychlost obnovy lze upravit pomocí softwarových parametrů. Čím vyšší je nastavená rychlost obnovy, tím rychlejší je obnova. Zrychlení obnovy zabere více CPU a síťových hardwarových zdrojů.
- Výkon CPU a šířka pásma sítě také ovlivní rychlost obnovy.
- Rychlost obnovy replikovaného poolu bude rychlejší než poolu s kódováním pro vymazání.
- Obecně mohou administrátoři zpomalit rychlost obnovy, aby snížili využití serverových zdrojů.
Referenční čas pro obnovu:
- NVMe SSD může trvat několik hodin.
- HDD může trvat přibližně jeden den.
Jak vybrat čísla K a M pro kódování pro vymazání?
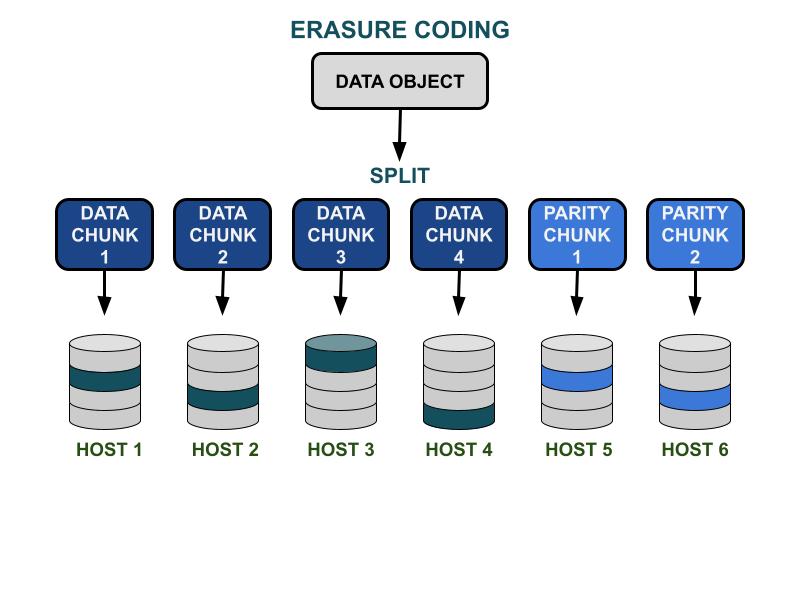
Jak funguje kódování pro vymazání.
Parametry kódování Ceph smazání K & M zahrnují efektivitu využitelné kapacity a redundanci proti selhání hardwaru. K je počet datových bloků a M je počet kódovacích bloků. Když klient zapíše datový objekt do úložiště Ceph, datový objekt bude rozdělen na K stejně velkých datových bloků. Ceph používá datové bloky k zakódování M bloků kódovacích bloků, které budou použity k výpočtu ztracených datových bloků, když dojde k selhání hardwaru. Data a kódové bloky budou distribuovány a uloženy v určené oblasti selhání K+M. Maximální počet datových bloků, které mohou být ztraceny, je M domén selhání. Dostupné domény selhání závisí na tom, jak jsou servery pro ukládání dat přiděleny v rámci fyzické infrastruktury. Pro malou Ceph cluster může selhání nastat na discích nebo serverových hostitelích. Doména selhání většího klastru může zahrnovat serverové skříně, serverové místnosti nebo datová centra, mimo jiné. Datový objekt je rekonstruován z datových bloků, když klient chce číst data.
Výkon úložiště
Ve srovnání s algoritmem replikace dat Ceph má kódování smazáním obvykle lepší efektivitu využití prostoru. Protože kód pro vymazání využívá více operací I/O na disku k dokončení datového I/O, je méně přívětivý k pracovním zátěžím vyžadujícím vysoký IOPS. Čím větší je součet K a M, tím více I/O operací spotřebovává zdroje diskových IOPS. Při použití většího K a menšího M bude celkový počet přenesených bajtů dat v síti Ceph clusteru menší. To by mohlo zvýšit výkon I/O propustnosti velkých datových objektů.
Účinnost prostoru
Účinnost využití prostoru v poolu pro kódování smazáním je rovna K/(K+M).Například prostorová efektivita kódu pro vymazání s K=4, M=2 je 4/6 = 66,7%.Toto je dvakrát efektivnější než replikace 3 pooly, které poskytují vyšší IOPS výkon se stejnou úrovní hardwarové redundance.
Rozumné K je větší než M kvůli efektivitě využitelného prostoru.Větší (K-M) kód pro vymazání dosahuje lepší prostorové efektivity.
Počet serverových hostitelů
Počet K+M také určuje počet hostitelů nebo větších domén selhání, které jsou v clusteru potřebné.
- Standardní pool pro kódování ztrát vyžaduje alespoň K + M serverových hostitelů pro efektivní distribuci všech EC chunků.
- Pokročilá konfigurace kódování ztrát umožňuje ukládat více EC chunků na doménu selhání. Tato konfigurace snižuje požadovaný počet serverů pro distribuci EC chunků.
Shrnutí vlivů kódování ztrát K & M:
- M určuje redundantní počet domén selhání.
- Větší K + M vede ke snížení výkonu IOPS pro malé objekty pro klienty, ale zlepšuje propustnost pro větší objekty.
- Účinnost úložného prostoru = K/(K+M)
- Minimální počet potřebných serverů.
Jaký je minimální počet hostitelů Ceph OSD potřebných k použití poolu pro kódování ztrát?
Nejlepší praxí při používání úložiště Ceph je nastavit doménu selhání poolu větší než "host". Datový pool používající hostitele jako doménu selhání instruuje Ceph, aby zapisoval části distribuovaně na různé hostitele, aby zajistil, že data mohou být obnovena pro jiné části uložené na jiných zdravých hostitelích. Uživatelé mohou stále konfigurovat doménu selhání na "disk", což chrání data specificky proti selhání disků, podobně jako tradiční diskové pole.
Zde jsou doporučení pro minimální počet hostitelů potřebných k použití poolu pro kódování smazáním.
Nejlepší konfigurace: Počet serverů ≧ K + M +1
- Tato konfigurace umožňuje Cephu distribuovat každý EC chunk mezi K+M hostiteli.
- Když jeden z hostitelů selže, máte dostatek hostitelů k obnovení ztraceného chunku.
Druhá nejlepší konfigurace: Počet serverů = K + M
- Tato konfigurace umožňuje distribuovat každý EC blok mezi K+M hostiteli.
- Když hostitel selže, nemáte žádného jiného hostitele, abyste obnovili ztracený EC blok. Je zásadní ho rychle opravit, abyste co nejdříve obnovili systém do zdravého stavu.
Konfigurace s omezeným rozpočtem: Počet serverů ≧ (K + M) / M
Tato konfigurace instruuje Ceph, aby rozložil několik chunků s kódováním pro vymazání mezi určený počet hostitelů.Když hostitel selže, maximálně M částí objektu bude ztraceno.
Tato konfigurace umožňuje
- Jakýkoli počet disků může selhat současně v jednom hostiteli.
- Nebo může cluster ztratit maximálně jednoho hostitele.
- Nebo může selhat pouze jeden disk v každém z M hostitelů současně.
Pro příklad K+M = 4+2 je minimální počet potřebných hostitelů 6/2 = 3. Můžete ztratit pouze jednoho hostitele, ale nebudete mít dostatek zdravých hostitelů v clusteru, abyste obnovili ztracené části.
Jak vypočítat použitelnou kapacitu clusteru Ceph?
Použitelný prostor v Ceph závisí na několika důležitých faktorech.
1.Maximální hrubá kapacita Ceph clusteru sestaveného z více serverů je součtem diskového prostoru v každém serveru.
Pokud cluster zahrnuje různé typy úložných zařízení, jako jsou HDD, SSD nebo NVMe disky, měli byste vypočítat celkový hrubý diskový prostor pro každý typ zařízení zvlášť.Ceph je schopen rozpoznat určenou třídu zařízení používanou každým poolem.
2. Ochrana dat aplikovaná na každý Ceph pool určuje použitelný prostor.
- Replikovaná ochrana: použitelný prostor = hrubá kapacita / velikost repliky
- Ochrana dat pomocí kódování: použitelný prostor = hrubá kapacita x (K / (K + M))
3. Ceph má určité režijní náklady na metadata a systémové operace. Použitý režijní prostor je přibližně 10 až 20 % v závislosti na vaší konkrétní konfiguraci a použití.
Všechna místa na discích jsou sdílena mezi všemi replikovanými a kódovanými pooly.
- Pooly mohou nastavit nebo nenastavit kvóty. Všechny kvóty jsou tenké provisioning.
- Protože dostupný prostor Ceph je tenký provisioning, úložný prostor je přidělován pouze tehdy, když je to potřeba, místo aby byl předem přidělen veškerý požadovaný prostor. To může zlepšit využití úložiště a snížit náklady na úložiště.
- Doporučuje se rezervovat 1/n prostor během provozu jako prostor pro obnovu dat v případě hardwarového selhání, kde n je počet serverů.
- Systém má přednastavené varování o využití 85 % téměř plného a 95 % plného.