FAQ sur le code d'effacement de stockage Ceph
Récemment, un client a posé plusieurs questions sur la façon dont le stockage Ceph utilise le code d'effacement pour protéger les données, éviter la corruption des données en cas de défaillance matérielle, le temps de récupération des données, comment choisir K+M, et le nombre minimum de serveurs requis pour Ceph. Nous croyons que de nombreux professionnels de l'informatique familiers avec les systèmes de stockage traditionnels seront intéressés à comprendre les caractéristiques de la nouvelle génération de stockage défini par logiciel. Je vais partager avec vous plusieurs questions que les clients posent souvent dans cet article.
Combien de temps Ceph mettra-t-il à récupérer d'une défaillance de disque Ceph ?
Le temps nécessaire pour récupérer des données d'une défaillance de périphérique de stockage dépend des conditions suivantes :
- Le temps de récupération des données n'est pas lié à la taille du disque dur. Le temps est proportionnel à la quantité de données stockées sur le disque. Ceph n'a besoin de restaurer que les données endommagées. Moins il y a de données endommagées, plus la réparation est rapide. Ceph ne reconstruit pas un disque comme le contrôleur RAID.
- Ceph répare les données sur les disques sains du cluster. Plus il y a de disques et d'hôtes dans le cluster, plus la récupération est rapide.
- La vitesse de récupération peut être ajustée par des paramètres logiciels. Plus la vitesse de récupération est élevée, plus la récupération est rapide. Accélérer la récupération occupera plus de ressources matérielles CPU et réseau.
- Les performances du CPU et la bande passante du réseau affecteront également la vitesse de récupération.
- La vitesse de récupération d'un pool répliqué sera plus rapide que celle d'un pool de code d'effacement.
- En général, les administrateurs peuvent ralentir la vitesse de récupération pour réduire l'utilisation des ressources du serveur.
Temps de référence pour la récupération :
- Un SSD NVMe pourrait prendre quelques heures.
- Un HDD pourrait prendre environ un jour.
Comment choisir les nombres K & M pour le code d'effacement ?
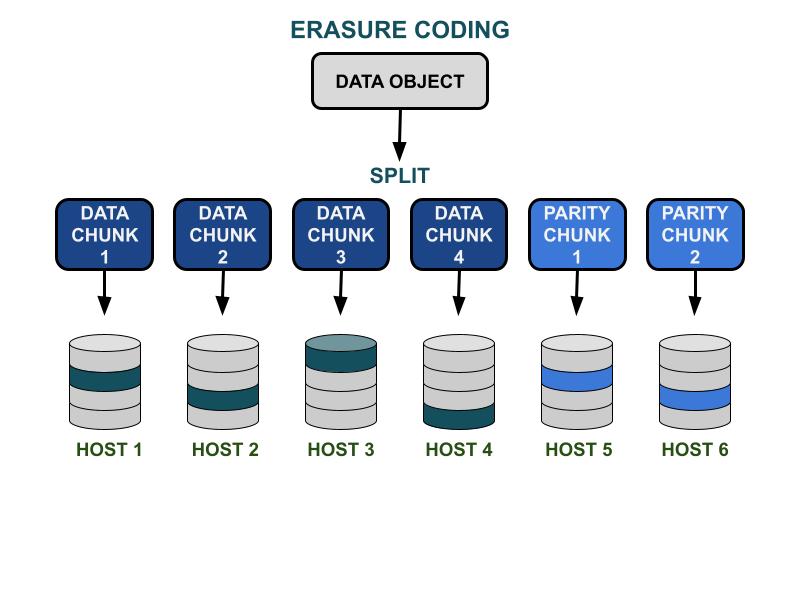
Comment fonctionne le code d'effacement.
Les paramètres de code d'effacement Ceph K & M impliquent l'efficacité de la capacité utilisable et la redondance contre les pannes matérielles. K est le nombre de morceaux de données, et M est le nombre de morceaux de codage. Lorsqu'un client écrit un objet de données dans le cluster de stockage Ceph, l'objet de données sera divisé en K morceaux de données de taille égale. Ceph utilise les morceaux de données pour encoder M morceaux de morceaux de code, qui seront utilisés pour calculer les morceaux de données perdus en cas de défaillance matérielle. Les morceaux de données et les morceaux de code seront distribués et stockés dans le domaine de défaillance spécifié par K+M. Le nombre maximum de morceaux de données qui peuvent être perdus est de M domaines de défaillance. Les domaines de défaillance disponibles dépendent de la manière dont les serveurs de stockage sont alloués au sein de l'infrastructure physique. Pour un cluster Ceph à petite échelle, la défaillance pourrait se produire sur les disques ou les hôtes serveurs. Le domaine de défaillance d'un cluster à plus grande échelle peut inclure des racks de serveurs, des salles de serveurs ou des centres de données, entre autres. L'objet de données est reconstruit à partir des morceaux de données lorsque le client souhaite lire les données.
Performance de stockage
Comparé à l'algorithme de réplication de données Ceph, le codage de suppression a généralement une meilleure efficacité d'espace utilisable. Parce que le code d'effacement utilise plus d'opérations d'E/S disque pour compléter l'E/S de données, il est moins adapté aux charges de travail exigeant des IOPS. Plus la somme de K et M est grande, plus les opérations d'E/S consommeront des ressources IOPS du disque. Lors de l'utilisation de K plus grand et de M plus petit, le nombre total d'octets de données transférées sur le réseau du cluster Ceph sera réduit. Cela pourrait augmenter les performances de débit d'entrée/sortie des objets de données de grande taille.
Efficacité spatiale
L'efficacité de l'espace utilisable d'un pool de codes d'effacement est égale à K/(K+M).Par exemple, l'efficacité spatiale du pool de codes d'effacement K=4, M=2 est de 4/6 = 66,7 %.C'est deux fois plus efficace que les pools de réplique 3, qui offrent des performances IOPS plus élevées avec le même niveau de redondance matérielle.
Un K raisonnable est plus grand que M en raison de l'efficacité de l'espace utilisable.Le code d'effacement (K-M) plus grand obtient une meilleure efficacité en termes d'espace.
Nombre d'hôtes de serveur
Le nombre de K+M détermine également le nombre d'hôtes ou de domaines de défaillance plus importants nécessaires dans le cluster.
- Un pool de code d'effacement standard nécessite au moins K + M hôtes de serveur pour distribuer efficacement tous les morceaux EC.
- Une configuration avancée de code d'effacement permet de stocker plusieurs morceaux EC par domaine de défaillance. Cette configuration réduit le nombre de serveurs requis pour distribuer les morceaux EC.
Résumé des influences du code d'effacement K & M :
- M détermine le nombre redondant de domaines de défaillance.
- Un K + M plus grand entraîne une réduction des performances IOPS des petits objets pour les clients, mais améliore le débit pour les objets plus volumineux.
- Efficacité de l'espace de stockage = K/(K+M)
- Nombre minimum de serveurs requis.
Quel est le nombre minimum d'hôtes Ceph OSD nécessaires pour utiliser le pool de code d'effacement ?
La meilleure pratique pour utiliser le stockage Ceph est de définir le domaine de défaillance du pool plus grand que le "hôte". Un pool de données utilisant un hôte comme domaine de défaillance indique à Ceph d'écrire des morceaux de manière distribuée sur différents hôtes afin de garantir que les données peuvent être récupérées pour d'autres morceaux sauvegardés sur d'autres hôtes sains. Les utilisateurs peuvent toujours configurer le domaine de défaillance sur "disque dur", ce qui protège les données spécifiquement contre les pannes de disque, similaire aux ensembles de disques traditionnels.
Voici les recommandations pour le nombre minimum d'hôtes requis pour utiliser un pool de code d'effacement.
Meilleure configuration : Nombre de serveurs ≧ K + M + 1
- Cette configuration permet à Ceph de distribuer chaque morceau EC sur K+M hôtes.
- Lorsque l'un des hôtes échoue, vous avez suffisamment d'hôtes pour restaurer le morceau perdu.
Deuxième meilleure configuration : Nombre de serveurs = K + M
- Cette configuration permet à chaque morceau EC d'être distribué sur K+M hôtes.
- Lorsqu'un hôte échoue, vous n'avez pas d'autre hôte pour restaurer le morceau EC perdu. Il est crucial de le réparer rapidement pour rétablir le système dans un état sain le plus rapidement possible.
Configuration limitée par le budget : Nombre de serveurs ≧ (K + M) / M
Cette configuration indique à Ceph de distribuer plusieurs morceaux codés par effacement sur le nombre désigné d'hôtes.Lorsqu'un hôte échoue, au maximum M morceaux d'un objet seront perdus.
Cette configuration permet
- Un nombre quelconque de disques peut échouer simultanément dans un hôte.
- Ou le cluster peut perdre au maximum un hôte.
- Ou seulement un disque dans chacun des M hôtes peut échouer simultanément.
Pour l'exemple de K+M = 4+2, le nombre minimum d'hôtes requis est 6/2 = 3. Vous ne pouvez perdre qu'un seul hôte, mais vous n'aurez pas assez d'hôtes sains dans le cluster pour réparer les morceaux perdus.
Comment calculer la capacité utilisable d'un cluster Ceph ?
L'espace utilisable dans Ceph dépend de plusieurs facteurs importants.
1.La capacité brute maximale d'un cluster Ceph construit par plusieurs serveurs est la somme de l'espace disque dans chaque serveur.
Si le cluster comprend différents types de dispositifs de stockage, tels que des HDD, des SSD ou des disques NVMe, vous devez calculer l'espace disque brut total pour chaque type de dispositif séparément.Ceph est capable de reconnaître la classe de périphérique désignée utilisée par chaque pool.
2. La protection des données appliquée à chaque pool Ceph détermine l'espace utilisable.
- Protection répliquée : espace utilisable = capacité brute/taille de la réplique
- Protection des données par code d'effacement : espace utilisable = capacité brute x (K/(K+M))
3. Ceph a un certain overhead pour les métadonnées et les opérations système. L'espace overhead utilisé est d'environ 10 à 20 % selon votre configuration et votre utilisation spécifiques.
Tout l'espace des disques est partagé entre tous les pools répliqués et par code d'effacement.
- Les pools peuvent définir ou ne pas définir de quotas. Tous les quotas sont en provisionnement fin.
- Parce que l'espace disponible de Ceph est en provisionnement fin, l'espace de stockage est alloué uniquement lorsque cela est nécessaire, plutôt que d'allouer tout l'espace requis à l'avance. Cela peut améliorer l'utilisation du stockage et réduire les coûts de stockage.
- Il est recommandé de réserver 1/n d'espace pendant l'opération comme espace de récupération des données en cas de défaillance matérielle, où n est le nombre de serveurs.
- Le système a des avertissements d'utilisation prédéfinis de 85 % presque plein et 95 % plein.