Preguntas frecuentes sobre el código de borrado de Ceph Storage
Recientemente, un cliente hizo varias preguntas sobre cómo el almacenamiento Ceph utiliza el Código de Borrado para proteger los datos, evitar la corrupción de datos en caso de falla de hardware, el tiempo de recuperación de datos, cómo elegir K+M y el número mínimo de servidores requeridos para Ceph. Creemos que muchos profesionales de TI familiarizados con sistemas de almacenamiento tradicionales estarán interesados en comprender las características de la nueva generación de almacenamiento definido por software. Compartiré contigo varias preguntas que los clientes suelen hacer en este artículo.
¿Cuánto tiempo tomará Ceph para recuperarse de una falla en el disco de Ceph?
El tiempo requerido para recuperar datos de una falla en un dispositivo de almacenamiento depende de las siguientes condiciones:
- El tiempo para recuperar los datos no está relacionado con el tamaño del disco duro. El tiempo es proporcional a la cantidad de datos almacenados en el disco. Ceph solo necesita restaurar los datos dañados. Cuantos menos datos estén dañados, más rápida será la reparación. Ceph no reconstruye un disco como lo hace el controlador RAID.
- Ceph vuelve a sanar los datos en los discos saludables del clúster. Cuantos más discos y hosts haya en el clúster, más rápida será la recuperación.
- La velocidad de recuperación se puede ajustar mediante parámetros de software. Cuanto mayor sea la velocidad de recuperación establecida, más rápida será la recuperación. Acelerar la recuperación ocupará más recursos de hardware de CPU y red.
- El rendimiento de la CPU y el ancho de banda de la red también afectarán la velocidad de recuperación.
- La velocidad de recuperación de un grupo replicado será más rápida que la del grupo de código de borrado.
- En general, los administradores pueden reducir la velocidad de recuperación para disminuir el uso de recursos del servidor.
Tiempo de referencia para la recuperación:
- Un SSD NVMe podría tardar unas pocas horas.
- Un HDD podría tardar alrededor de un día.
¿Cómo elegir los números K y M del código de borrado?
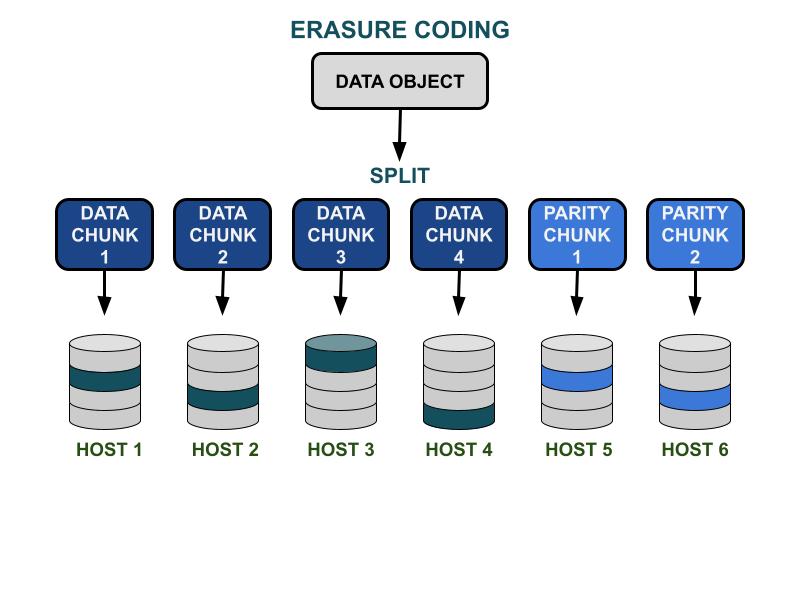
Cómo funciona el código de borrado.
Los parámetros de código de borrado Ceph K y M implican la eficiencia de capacidad utilizable y la redundancia contra fallos de hardware. K es el número de fragmentos de datos, y M es el número de fragmentos de codificación. Cuando un cliente escribe un objeto de datos en el clúster de almacenamiento Ceph, el objeto de datos se dividirá en K fragmentos de datos de igual tamaño. Ceph utiliza los fragmentos de datos para codificar M fragmentos de codificación, que se utilizarán para calcular los fragmentos de datos perdidos cuando falle el hardware. Los fragmentos de datos y los fragmentos de código se distribuirán y almacenarán en el dominio de falla especificado por K+M. El número máximo de fragmentos de datos que se pueden perder es M dominios de falla. Los dominios de falla disponibles dependen de cómo se asignan los servidores de almacenamiento dentro de la infraestructura física. Para un clúster Ceph de pequeña escala, la falla podría estar en los discos o en los servidores. El dominio de falla de un clúster a gran escala puede incluir estantes de servidores, salas de servidores o centros de datos, entre otros. El objeto de datos se reconstruye a partir de los fragmentos de datos cuando el cliente quiere leer los datos.
Rendimiento de almacenamiento
En comparación con el algoritmo de replicación de datos Ceph, la codificación de borrado generalmente tiene una mejor eficiencia de espacio utilizable. Debido a que el código de borrado utiliza más operaciones de entrada/salida de disco para completar la entrada/salida de datos, es menos amigable para las cargas de trabajo que demandan IOPS. Cuanto mayor sea la suma de K y M, más operaciones de I/O consumirán los recursos de IOPS del disco. Al usar K más grandes y M más pequeños, el número total de bytes de datos transferidos en la red del clúster Ceph será menor. Esto podría aumentar el rendimiento de la capacidad de entrada/salida de objetos de datos de gran tamaño.
Eficiencia del espacio
La eficiencia del espacio utilizable de un grupo de códigos de borrado es igual a K/(K+M).Por ejemplo, la eficiencia espacial del grupo de códigos de borrado K=4, M=2 es 4/6 = 66.7%.Esto es el doble de eficiente que los grupos de réplica 3, que proporcionan un rendimiento IOPS más alto con el mismo nivel de redundancia de hardware.
K razonable es mayor que M debido a la eficiencia del espacio utilizable.El código de borrado (K-M) más grande obtiene una mejor eficiencia de espacio.
Número de hosts de servidor
El número de K+M también determina el número de hosts o dominios de falla más grandes que se requieren en el clúster.
- Un grupo de códigos de borrado estándar requiere al menos K + M hosts de servidor para distribuir eficazmente todos los fragmentos de EC.
- Una configuración avanzada de código de borrado permite almacenar múltiples fragmentos de EC por dominio de falla. Esta configuración reduce el número de servidores requeridos para distribuir fragmentos de EC.
Resumen de las influencias del código de borrado K & M:
- M determina el número redundante de dominios de falla.
- Un K + M más grande resulta en un rendimiento de IOPS de objetos pequeños reducido para los clientes, pero mejora el rendimiento para objetos más grandes.
- Eficiencia del espacio de almacenamiento = K/(K+M)
- Número mínimo de servidores requeridos.
¿Cuál es el número mínimo de hosts Ceph OSD necesarios para usar el grupo de códigos de borrado?
La mejor práctica al usar el almacenamiento Ceph es establecer el dominio de falla del pool más grande que el "host". Un pool de datos que utiliza un host como dominio de falla instruye a Ceph a escribir fragmentos de manera distribuida en diferentes hosts para garantizar que los datos puedan ser recuperados de otros fragmentos guardados en otros hosts saludables. Los usuarios aún pueden configurar el dominio de falla a "unidad de disco", lo que protege los datos específicamente contra fallas de disco, similar a los arreglos de disco tradicionales.
Aquí están las recomendaciones para el número mínimo de hosts requeridos para usar un grupo de código de borrado.
Mejor configuración: Número de servidores ≧ K + M +1
- Esta configuración permite a Ceph distribuir cada fragmento EC entre K+M hosts.
- Cuando uno de los hosts falla, tienes suficientes hosts para restaurar el fragmento perdido.
Segunda mejor configuración: Número de servidores = K + M
- Esta configuración permite que cada fragmento de EC se distribuya entre K+M hosts.
- Cuando un host falla, no tienes otro host para restaurar el fragmento de EC perdido. Es crucial repararlo rápidamente para restaurar el sistema a un estado saludable lo antes posible.
Configuración limitada por presupuesto: Número de servidores ≧ (K + M) / M
Esta configuración instruye a Ceph a distribuir varios fragmentos codificados por borrado entre el número designado de hosts.Cuando un host falla, se perderán como máximo M fragmentos de un objeto.
Esta configuración permite
- Cualquier número de discos puede fallar simultáneamente en un host.
- O el clúster puede perder como máximo un host.
- O solo un disco en cada uno de los M hosts puede fallar simultáneamente.
Para el ejemplo de K+M = 4+2, el número mínimo de hosts requeridos es 6/2 = 3. Puedes perder solo un host, pero no tendrás suficientes hosts saludables en el clúster para recuperar los fragmentos perdidos.
¿Cómo calcular la capacidad utilizable de un clúster Ceph?
El espacio utilizable en Ceph depende de varios factores importantes.
1.La capacidad bruta máxima de un clúster Ceph construido por múltiples servidores es la suma del espacio en disco en cada servidor.
Si el clúster incluye varios tipos de dispositivos de almacenamiento, como HDD, SSD o unidades NVMe, debes calcular el espacio total en disco bruto para cada tipo de dispositivo por separado.Ceph es capaz de reconocer la clase de dispositivo designada utilizada por cada pool.
2. La protección de datos aplicada a cada grupo de Ceph determina el espacio utilizable.
- Protección replicada: espacio utilizable = capacidad bruta/tamaño de réplica
- Protección de datos por código de borrado: espacio utilizable = capacidad bruta x (K/(K+M))
3. Ceph tiene un overhead para metadatos y operaciones del sistema. El espacio de overhead utilizado es de alrededor del 10 al 20% dependiendo de tu configuración y uso específicos.
Todo el espacio del disco duro se comparte entre todos los grupos replicados y de código de borrado.
- Los grupos pueden establecer o no establecer cuotas. Todas las cuotas son de aprovisionamiento delgado.
- Debido a que el espacio disponible de Ceph es de aprovisionamiento delgado, el espacio de almacenamiento se asigna solo cuando es necesario, en lugar de asignar todo el espacio requerido por adelantado. Esto puede mejorar la utilización del almacenamiento y reducir los costos de almacenamiento.
- Se recomienda reservar 1/n de espacio durante la operación como espacio de recuperación de datos en caso de falla de hardware, donde n es el número de servidores.
- El sistema tiene advertencias de uso preestablecidas del 85% casi lleno y 95% lleno.