คำถามที่พบบ่อยเกี่ยวกับรหัสลบข้อมูลการจัดเก็บข้อมูล Ceph
เมื่อเร็ว ๆ นี้ ลูกค้าได้สอบถามคำถามหลายข้อเกี่ยวกับวิธีที่ Ceph storage ใช้ Erasure Code เพื่อปกป้องข้อมูล หลีกเลี่ยงการเสียหายของข้อมูลในกรณีที่ฮาร์ดแวร์ล้มเหลว เวลาในการกู้คืนข้อมูล วิธีการเลือก K+M และจำนวนเซิร์ฟเวอร์ขั้นต่ำที่จำเป็นสำหรับ Ceph. เรามีความเชื่อว่ามืออาชีพด้านไอทีหลายคนที่คุ้นเคยกับระบบจัดเก็บข้อมูลแบบดั้งเดิมจะสนใจในการทำความเข้าใจฟีเจอร์ของระบบจัดเก็บข้อมูลที่กำหนดโดยซอฟต์แวร์รุ่นใหม่. ฉันจะแบ่งปันคำถามหลายข้อที่ลูกค้ามักถามในบทความนี้.
Ceph จะใช้เวลานานแค่ไหนในการกู้คืนจากความล้มเหลวของดิสก์ Ceph?
เวลาที่ใช้ในการกู้คืนข้อมูลจากความล้มเหลวของอุปกรณ์จัดเก็บข้อมูลขึ้นอยู่กับเงื่อนไขต่อไปนี้:
- เวลาในการกู้คืนข้อมูลไม่เกี่ยวข้องกับขนาดของฮาร์ดดิสก์ เวลาเป็นสัดส่วนกับปริมาณข้อมูลที่เก็บไว้ในดิสก์ Ceph เพียงแค่ต้องกู้คืนข้อมูลที่เสียหาย ยิ่งข้อมูลเสียหายน้อยเท่าไหร่ การซ่อมแซมก็จะยิ่งเร็วขึ้น Ceph ไม่ได้สร้างดิสก์ใหม่เหมือนกับ RAID controller.
- Ceph จะทำการฟื้นฟูข้อมูลไปยังดิสก์ที่มีสุขภาพดีในคลัสเตอร์ ยิ่งมีดิสก์และโฮสต์ในคลัสเตอร์มากเท่าไหร่ การกู้คืนก็จะยิ่งเร็วขึ้นเท่านั้น
- ความเร็วในการกู้คืนสามารถปรับได้โดยพารามิเตอร์ซอฟต์แวร์ ยิ่งตั้งความเร็วในการกู้คืนสูงเท่าไหร่ การกู้คืนก็จะยิ่งเร็วขึ้น การเร่งความเร็วในการกู้คืนจะใช้ทรัพยากร CPU และฮาร์ดแวร์เครือข่ายมากขึ้น
- ประสิทธิภาพของ CPU และแบนด์วิธเครือข่ายก็จะมีผลต่อความเร็วในการกู้คืนเช่นกัน
- ความเร็วในการกู้คืนของพูลที่ทำซ้ำจะเร็วกว่าพูลที่ใช้รหัสการลบ
- โดยทั่วไป ผู้ดูแลระบบสามารถชะลอความเร็วในการกู้คืนเพื่อลดการใช้ทรัพยากรของเซิร์ฟเวอร์
เวลาที่อ้างอิงสำหรับการกู้คืน:
- NVMe SSD อาจใช้เวลาหลายชั่วโมง
- HDD อาจใช้เวลาประมาณหนึ่งวัน
จะเลือกหมายเลข Erasure Code K & M ได้อย่างไร?
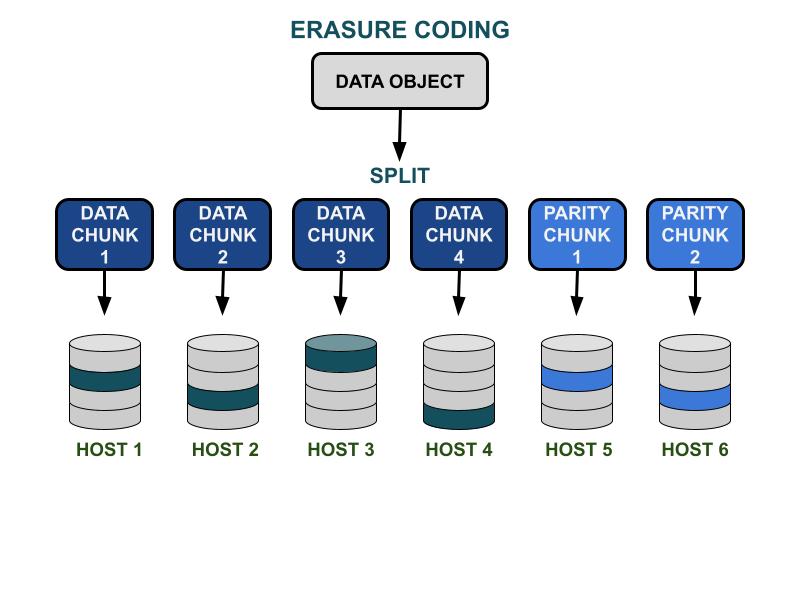
การทำงานของรหัสการลบ
พารามิเตอร์รหัสการลบ Ceph K & M เกี่ยวข้องกับประสิทธิภาพความจุที่ใช้งานได้และความซ้ำซ้อนต่อความล้มเหลวของฮาร์ดแวร์. K คือจำนวนของข้อมูลที่แบ่งออกเป็นชิ้นส่วน และ M คือจำนวนของชิ้นส่วนที่เข้ารหัส. เมื่อไคลเอนต์เขียนอ็อบเจ็กต์ข้อมูลไปยังคลัสเตอร์จัดเก็บ Ceph อ็อบเจ็กต์ข้อมูลจะถูกแบ่งออกเป็น K ชิ้นข้อมูลที่มีขนาดเท่ากัน. Ceph ใช้ข้อมูลชิ้นส่วนเพื่อเข้ารหัส M ชิ้นส่วนของชิ้นส่วนการเข้ารหัส ซึ่งจะถูกใช้ในการคำนวณชิ้นส่วนข้อมูลที่สูญหายเมื่อฮาร์ดแวร์ล้มเหลว. ข้อมูลชิ้นและรหัสจะถูกแจกจ่ายและเก็บไว้ในโดเมนความล้มเหลวที่ระบุโดย K+M. จำนวนสูงสุดของข้อมูลที่สามารถสูญหายได้คือ M โดเมนที่ล้มเหลว. โดเมนความล้มเหลวที่มีอยู่ขึ้นอยู่กับการจัดสรรเซิร์ฟเวอร์จัดเก็บข้อมูลภายในโครงสร้างพื้นฐานทางกายภาพ. สำหรับคลัสเตอร์ Ceph ขนาดเล็ก ความล้มเหลวอาจเกิดขึ้นที่ดิสก์หรือโฮสต์เซิร์ฟเวอร์. โดเมนความล้มเหลวของคลัสเตอร์ขนาดใหญ่สามารถรวมถึงตู้เซิร์ฟเวอร์, ห้องเซิร์ฟเวอร์, หรือศูนย์ข้อมูล เป็นต้น. วัตถุข้อมูลจะถูกสร้างขึ้นใหม่จากข้อมูลชิ้นส่วนเมื่อไคลเอนต์ต้องการอ่านข้อมูล.
ประสิทธิภาพการจัดเก็บ
เมื่อเปรียบเทียบกับอัลกอริธึมการทำสำเนาข้อมูล Ceph การเข้ารหัสการลบมักมีประสิทธิภาพในการใช้พื้นที่ที่ดีกว่า เนื่องจากรหัสการลบใช้การดำเนินการ I/O ของดิสก์มากขึ้นเพื่อให้เสร็จสิ้นการ I/O ของข้อมูล จึงไม่เป็นมิตรกับงานที่ต้องการ IOPS สูง. ยิ่งผลรวมของ K และ M มากเท่าไหร่ การดำเนินการ I/O ก็จะใช้ทรัพยากร IOPS ของดิสก์มากขึ้นเท่านั้น. เมื่อใช้ K ที่ใหญ่กว่าและ M ที่เล็กกว่า จำนวนไบต์ทั้งหมดของข้อมูลที่ถ่ายโอนในเครือข่าย Ceph cluster จะน้อยลง. สิ่งนี้อาจเพิ่มประสิทธิภาพการส่งผ่าน I/O ของวัตถุข้อมูลขนาดใหญ่.
ประสิทธิภาพการใช้พื้นที่
ประสิทธิภาพการใช้พื้นที่ที่สามารถใช้งานได้ของพูลรหัสลบจะเท่ากับ K/(K+M).ตัวอย่างเช่น ประสิทธิภาพการใช้พื้นที่ของพูลรหัสการลบ K=4, M=2 คือ 4/6 = 66.7%.นี่มีประสิทธิภาพมากกว่าสระ replica 3 ถึงสองเท่า ซึ่งให้ประสิทธิภาพ IOPS ที่สูงกว่าด้วยระดับความซ้ำซ้อนของฮาร์ดแวร์ที่เท่ากัน.
K ที่สมเหตุสมผลมีขนาดใหญ่กว่า M เนื่องจากประสิทธิภาพของพื้นที่ที่ใช้งานได้.รหัสการลบขนาดใหญ่ (K-M) จะมีประสิทธิภาพในการใช้พื้นที่ที่ดีกว่า.
จำนวนโฮสต์เซิร์ฟเวอร์
จำนวน K+M ยังกำหนดจำนวนโฮสต์หรือโดเมนความล้มเหลวที่ใหญ่กว่าที่จำเป็นในคลัสเตอร์อีกด้วย
- พูลรหัสการลบมาตรฐานต้องการโฮสต์เซิร์ฟเวอร์อย่างน้อย K + M เพื่อกระจายชิ้นส่วน EC ทั้งหมดอย่างมีประสิทธิภาพ
- การกำหนดค่ารหัสการลบขั้นสูงอนุญาตให้เก็บชิ้นส่วน EC หลายชิ้นต่อโดเมนความล้มเหลว การกำหนดค่านี้ช่วยลดจำนวนเซิร์ฟเวอร์ที่จำเป็นสำหรับการกระจายชิ้นส่วน EC
สรุปอิทธิพลของรหัสการลบ K & M:
- M กำหนดจำนวนโดเมนความล้มเหลวที่ซ้ำซ้อน
- K + M ที่ใหญ่กว่าจะส่งผลให้ประสิทธิภาพ IOPS ของวัตถุขนาดเล็กลดลงสำหรับลูกค้า แต่จะปรับปรุงการส่งข้อมูลสำหรับวัตถุขนาดใหญ่
- ประสิทธิภาพของพื้นที่จัดเก็บ = K/(K+M)
- จำนวนเซิร์ฟเวอร์ขั้นต่ำที่ต้องการ
จำนวนโฮสต์ Ceph OSD ขั้นต่ำที่จำเป็นในการใช้พูลรหัสการลบคืออะไร?
แนวทางปฏิบัติที่ดีที่สุดในการใช้ Ceph storage คือการตั้งค่าโดเมนความล้มเหลวของพูลให้ใหญ่กว่าคำว่า "โฮสต์" พูลข้อมูลที่ใช้โฮสต์เป็นโดเมนความล้มเหลวจะสั่งให้ Ceph เขียนชิ้นส่วนข้อมูลแบบกระจายไปยังโฮสต์ต่างๆ เพื่อให้แน่ใจว่าข้อมูลสามารถกู้คืนได้สำหรับชิ้นส่วนข้อมูลอื่นๆ ที่บันทึกไว้ในโฮสต์ที่มีสุขภาพดีอื่นๆ ผู้ใช้ยังสามารถกำหนดค่าโดเมนความล้มเหลวเป็น "ดิสก์ไดรฟ์" ซึ่งจะปกป้องข้อมูลโดยเฉพาะจากความล้มเหลวของดิสก์ คล้ายกับอาร์เรย์ดิสก์แบบดั้งเดิม.
นี่คือคำแนะนำสำหรับจำนวนโฮสต์ขั้นต่ำที่จำเป็นในการใช้พูลรหัสการลบ.
การกำหนดค่าที่ดีที่สุด: จำนวนเซิร์ฟเวอร์ ≧ K + M +1
- การตั้งค่านี้ช่วยให้ Ceph สามารถกระจายทุกชิ้นส่วน EC ไปยังโฮสต์ K+M.
- เมื่อโฮสต์ใดโฮสต์หนึ่งล้มเหลว คุณจะมีโฮสต์เพียงพอในการกู้คืนชิ้นส่วนที่หายไป.
การกำหนดค่าที่สองที่ดีที่สุด: จำนวนเซิร์ฟเวอร์ = K + M
- การตั้งค่านี้อนุญาตให้แต่ละชิ้นส่วน EC ถูกกระจายไปยังโฮสต์ K+M.
- เมื่อโฮสต์ล้มเหลว คุณจะไม่มีโฮสต์อื่นในการกู้คืนชิ้นส่วน EC ที่สูญหาย การซ่อมแซมมันอย่างรวดเร็วเป็นสิ่งสำคัญเพื่อคืนระบบให้กลับสู่สภาพที่ดีโดยเร็วที่สุด.
การกำหนดค่าที่มีงบประมาณจำกัด: จำนวนเซิร์ฟเวอร์ ≧ (K + M) / M
การกำหนดค่านี้สั่งให้ Ceph กระจายชิ้นส่วนที่เข้ารหัสการลบหลายชิ้นไปยังจำนวนโฮสต์ที่กำหนด.เมื่อโฮสต์ล้มเหลว จะมีชิ้นส่วนของวัตถุสูญหายได้มากที่สุด M ชิ้น.
การกำหนดค่านี้อนุญาตให้
- ดิสก์จำนวนมากสามารถล้มเหลวพร้อมกันในโฮสต์เดียวได้.
- หรือคลัสเตอร์สามารถสูญเสียโฮสต์ได้สูงสุดหนึ่งโฮสต์.
- หรือดิสก์เพียงหนึ่งในแต่ละโฮสต์ M สามารถล้มเหลวพร้อมกัน.
สำหรับตัวอย่างของ K+M = 4+2 จำนวนโฮสต์ขั้นต่ำที่ต้องการคือ 6/2 = 3. คุณสามารถสูญเสียโฮสต์ได้เพียงหนึ่งโฮสต์ แต่คุณจะไม่มีโฮสต์ที่มีสุขภาพดีเพียงพอในคลัสเตอร์เพื่อฟื้นฟูชิ้นส่วนที่สูญหาย.
วิธีการคำนวณความจุที่ใช้งานได้ของคลัสเตอร์ Ceph?
พื้นที่ที่ใช้งานได้ใน Ceph ขึ้นอยู่กับปัจจัยสำคัญหลายประการ.
1.ความจุดิบสูงสุดของคลัสเตอร์ Ceph ที่สร้างขึ้นโดยเซิร์ฟเวอร์หลายเครื่องคือผลรวมของพื้นที่ดิสก์ในแต่ละเซิร์ฟเวอร์.
หากคลัสเตอร์รวมอุปกรณ์จัดเก็บข้อมูลประเภทต่างๆ เช่น HDD, SSD หรือ NVMe คุณควรคำนวณพื้นที่ดิสก์ดิบรวมสำหรับแต่ละประเภทอุปกรณ์แยกกัน.Ceph สามารถระบุประเภทอุปกรณ์ที่กำหนดไว้ซึ่งใช้โดยแต่ละพูลได้.
2. การป้องกันข้อมูลที่ใช้กับแต่ละ Ceph pool จะกำหนดพื้นที่ที่ใช้งานได้.
- การป้องกันแบบทำซ้ำ: พื้นที่ที่ใช้งานได้ = ความจุดิบ/ขนาดสำเนา
- การป้องกันข้อมูลแบบ Erasure Code: พื้นที่ที่ใช้งานได้ = ความจุดิบ x (K/(K+M))
3. Ceph มีค่าใช้จ่ายเพิ่มเติมสำหรับข้อมูลเมตาและการดำเนินการของระบบ ค่าใช้จ่ายเพิ่มเติมที่ใช้จะอยู่ที่ประมาณ 10 ถึง 20% ขึ้นอยู่กับการกำหนดค่าและการใช้งานเฉพาะของคุณ.
พื้นที่ของดิสก์ทั้งหมดจะแบ่งปันกันระหว่างทุก pool ที่ทำซ้ำและ Erasure Code
- Pools สามารถตั้งค่าหรือไม่ตั้งค่าโควต้าได้ โควต้าทั้งหมดเป็นการจัดสรรแบบบาง
- เนื่องจากพื้นที่ที่มีอยู่ของ Ceph เป็นการจัดสรรแบบบาง พื้นที่จัดเก็บจะถูกจัดสรรเฉพาะเมื่อจำเป็น ไม่ใช่การจัดสรรพื้นที่ทั้งหมดที่ต้องการล่วงหน้า ซึ่งสามารถปรับปรุงการใช้พื้นที่จัดเก็บและลดต้นทุนการจัดเก็บ.
- แนะนำให้สำรองพื้นที่ 1/n ในระหว่างการดำเนินการเป็นพื้นที่กู้คืนข้อมูลในกรณีที่เกิดความล้มเหลวของฮาร์ดแวร์ โดยที่ n คือจำนวนเซิร์ฟเวอร์.
- ระบบมีการตั้งค่าการเตือนการใช้งานล่วงหน้าที่ 85% ใกล้เต็มและ 95% เต็ม.