Veelgestelde vragen over Ceph-opslagverwijderingscode
Onlangs stelde een klant verschillende vragen over hoe Ceph-opslag Erasure Code gebruikt om gegevens te beschermen, gegevenscorruptie te voorkomen in het geval van hardwarestoringen, de tijd voor gegevensherstel, hoe K+M te kiezen en het minimale aantal servers dat nodig is voor Ceph. Wij geloven dat veel IT-professionals die bekend zijn met traditionele opslagsystemen geïnteresseerd zullen zijn in het begrijpen van de kenmerken van de nieuwe generatie softwaregedefinieerde opslag. Ik zal in dit artikel verschillende vragen met je delen die klanten vaak stellen.
Hoe lang zal Ceph nodig hebben om te herstellen van een Ceph-schijfstoring?
De tijd die nodig is om gegevens te herstellen van een opslagapparaatstoring hangt af van de volgende voorwaarden:
- De tijd voor het herstellen van de gegevens is niet gerelateerd aan de grootte van de harde schijf. De tijd is evenredig met de hoeveelheid gegevens die op de schijf zijn opgeslagen. Ceph hoeft alleen de beschadigde gegevens te herstellen. Hoe minder gegevens beschadigd zijn, hoe sneller de reparatie. Ceph bouwt een schijf niet opnieuw op zoals de RAID-controller.
- Ceph herstelt de gegevens naar de gezonde schijven in de cluster. Hoe meer schijven en hosts in de cluster, hoe sneller het herstel.
- De herstelsnelheid kan worden aangepast met softwareparameters. Hoe hoger de herstelsnelheid is ingesteld, hoe sneller het herstel. Het versnellen van het herstel zal meer CPU- en netwerkhardwarebronnen verbruiken.
- CPU-prestaties en netwerkbandbreedte zullen ook de herstelsnelheid beïnvloeden.
- De herstelsnelheid van een gerepliceerde pool zal sneller zijn dan die van de wissen-code pool.
- Over het algemeen kunnen beheerders de herstelsnelheid vertragen om het gebruik van serverbronnen te verminderen.
Referentietijd voor herstel:
- NVMe SSD kan enkele uren duren.
- HDD kan ongeveer één dag duren.
Hoe de Erasure Code K & M nummers te kiezen?
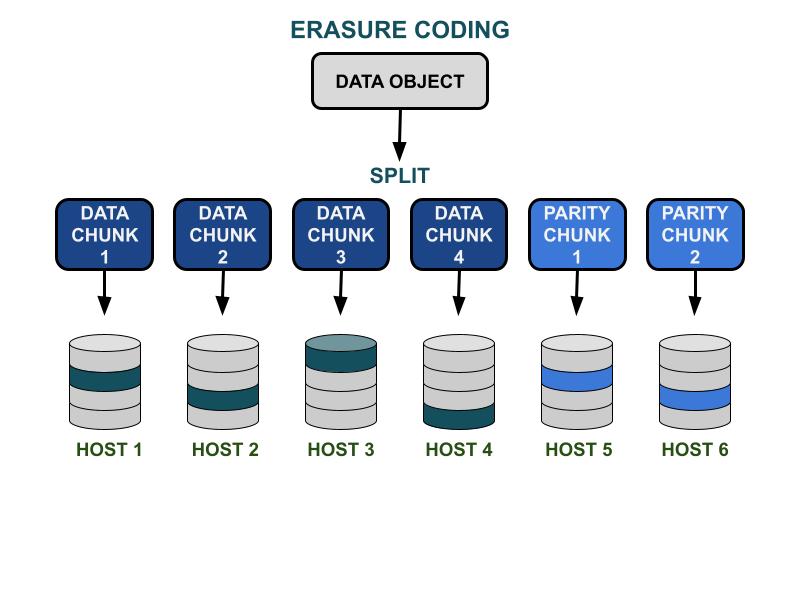
Hoe wissen-code werkt.
De Ceph-foutencoderingparameters K & M hebben betrekking op de bruikbare capaciteitsefficiëntie en redundantie tegen hardwarestoringen. K is het aantal datablokken, en M is het aantal codeblokken. Wanneer een klant een dataobject naar het Ceph-opslagcluster schrijft, wordt het dataobject verdeeld in K gelijke datablokken. Ceph gebruikt de datablokken om M blokken codering te coderen, die zullen worden gebruikt om de verloren datablokken te berekenen wanneer de hardware faalt. Gegevensstukken en codefragmenten zullen worden verdeeld en opgeslagen in het door K+M gespecificeerde faalgebied. Het maximale aantal datablokken dat verloren kan gaan is M foutdomeinen. De beschikbare faalgebieden zijn afhankelijk van hoe de opslagservers zijn toegewezen binnen de fysieke infrastructuur. Voor een kleinschalig Ceph-cluster kan de storing op schijf of serverhosts zijn. Het faalgebied van een cluster op grotere schaal kan onder andere serverrekken, serverruimtes of datacenters omvatten. Het gegevensobject wordt opnieuw opgebouwd uit de gegevensfragmenten wanneer de client de gegevens wil lezen.
Opslagprestaties
In vergelijking met het Ceph-datareplicatie-algoritme heeft erasure coding meestal een betere bruikbare ruimte-efficiëntie. Omdat de wissen-code meer schijf I/O-bewerkingen gebruikt om de gegevens I/O te voltooien, is het minder vriendelijk voor de IOPS-eisende werklasten. Hoe groter de som van K en M, hoe meer I/O-bewerkingen schijfiopsbronnen zullen verbruiken. Bij het gebruik van grotere K en kleinere M zal het totale aantal overgedragen bytes aan gegevens op het Ceph-clusternetwerk minder zijn. Dit kan de I/O-doorvoersnelheid van grote gegevensobjecten verhogen.
Ruimte-efficiëntie
De bruikbare ruimte-efficiëntie van een wissen-codepool is gelijk aan K/(K+M).Bijvoorbeeld, de ruimte-efficiëntie van de K=4, M=2 wissen code pool is 4/6 = 66,7%.Dit is twee keer zo efficiënt als replica 3 pools, die hogere IOPS-prestaties bieden met hetzelfde niveau van hardware-redundantie.
Redelijk K is groter dan M vanwege de bruikbare ruimte-efficiëntie.De grotere (K-M) wissen code biedt een betere ruimte-efficiëntie.
Aantal serverhosts
Het aantal K+M bepaalt ook het aantal hosts of grotere foutdomeinen die nodig zijn in de cluster.
- Een standaard wissen-codepool vereist minimaal K + M serverhosts om alle EC-chunks effectief te verdelen.
- Een geavanceerde wissen-codeconfiguratie maakt het mogelijk om meerdere EC-chunks per foutdomein op te slaan. Deze configuratie vermindert het vereiste aantal servers voor het verdelen van EC-chunks.
Samenvatting van de invloeden van wissen-code K & M:
- M bepaalt het redundante aantal foutdomeinen.
- Een groter K + M resulteert in verminderde IOPS-prestaties voor kleine objecten voor clients, maar verbetert de doorvoer voor grotere objecten.
- Opslagruimte-efficiëntie = K/(K+M)
- Minimaal aantal vereiste servers.
Wat is het minimale aantal Ceph OSD-hosts dat nodig is om de wissen-codepool te gebruiken?
De beste praktijk voor het gebruik van Ceph-opslag is om het foutdomein van de pool groter in te stellen dan de "host". Een datapool die een host als het foutdomein gebruikt, instrueert Ceph om chunks verspreid over verschillende hosts te schrijven, zodat gegevens kunnen worden hersteld voor andere chunks die zijn opgeslagen op andere gezonde hosts. Gebruikers kunnen het foutdomein nog steeds configureren op "schijf", wat gegevens specifiek beschermt tegen schijfstoringen, vergelijkbaar met traditionele schijfarrays.
Hier zijn de aanbevelingen voor het minimale aantal hosts dat nodig is om een foutencodering pool te gebruiken.
Beste configuratie: Aantal servers ≧ K + M +1
- Deze configuratie stelt Ceph in staat om elke EC-chunk over K+M hosts te verdelen.
- Wanneer een van de hosts faalt, heb je genoeg hosts om de verloren chunk te herstellen.
Op één na beste configuratie: Aantal servers = K + M
- Deze configuratie stelt elke EC-chunk in staat om over K+M hosts te worden verdeeld.
- Wanneer een host faalt, heb je geen andere host om de verloren EC-chunk te herstellen. Het is cruciaal om het snel te repareren om het systeem zo snel mogelijk weer in een gezonde staat te brengen.
Budget-beperkte configuratie: Aantal servers ≧ (K + M) / M
Deze configuratie instrueert Ceph om verschillende erasure-gecodeerde stukken over het aangewezen aantal hosts te verdelen.Wanneer een host faalt, zullen er maximaal M stukken van een object verloren gaan.
Deze configuratie staat toe
- Een onbeperkt aantal schijven kan gelijktijdig in één host uitvallen.
- Of het cluster kan maximaal één host verliezen.
- Of slechts één schijf in elk van de M hosts kan gelijktijdig uitvallen.
Voor het voorbeeld van K+M = 4+2 is het minimum aantal vereiste hosts 6/2 = 3. Je kunt slechts één host verliezen, maar je hebt niet genoeg gezonde hosts in het cluster om de verloren chunks opnieuw te herstellen.
Hoe bereken je de bruikbare capaciteit van een Ceph-cluster?
De bruikbare ruimte in Ceph hangt af van verschillende belangrijke factoren.
1.De maximale ruwe capaciteit van een Ceph-cluster dat is opgebouwd uit meerdere servers is de som van de schijfruimte in elke server.
Als het cluster verschillende soorten opslagapparaten bevat, zoals HDD's, SSD's of NVMe-schijven, moet je de totale ruwe schijfruimte voor elk type apparaat afzonderlijk berekenen.Ceph is in staat om de aangewezen apparaatsklasse die door elke pool wordt gebruikt te herkennen.
2. De gegevensbescherming die op elke Ceph-pool wordt toegepast, bepaalt de bruikbare ruimte.
- Gerepliceerde bescherming: bruikbare ruimte = ruwe capaciteit/replika-grootte
- Erasure Code gegevensbescherming: bruikbare ruimte = ruwe capaciteit x (K/(K+M))
3. Ceph heeft enige overhead voor metadata en systeemoperaties. De gebruikte overheadruimte is ongeveer 10 tot 20%, afhankelijk van uw specifieke configuratie en gebruik.
Alle schijfruimte wordt gedeeld tussen alle gerepliceerde en erasure code pools.
- Pools kunnen quota instellen of niet instellen. Alle quota zijn dunne provisioning.
- Omdat de beschikbare ruimte van Ceph dunne provisioning is, wordt opslagruimte alleen toegewezen wanneer dat nodig is, in plaats van alle vereiste ruimte vooraf toe te wijzen. Dit kan de opslagbenutting verbeteren en de opslagkosten verlagen.
- Het wordt aanbevolen om tijdens de werking 1/n ruimte te reserveren als gegevensherstelruimte in geval van hardwarestoringen, waarbij n het aantal servers is.
- Het systeem heeft vooraf ingestelde gebruikswaarschuwingen van 85% bijna vol en 95% vol.