S3 Storage Load Balancing for AI with Ceph RGW
AI workloads require scalable, high-throughput S3 storage for training data, models, and inference outputs. Ceph RGW offers a reliable, S3-compatible backend, but performance depends heavily on load balancing. For private AI clusters using NVMe, LVS TUN provides near line-rate bandwidth and low latency. Ambedded’s UniVirStor natively supports LVS TUN with automated setup and HA design, making it ideal for performance-critical AI storage environments.
The following key points summarize the need and justification for each design choice.
- Why AI Needs Scalable and Efficient Storage
- Why S3 is Ideal for AI Workloads
- Why Ceph RGW Is a Strong Fit for AI S3 Storage
- The Need for High-Availability Load Balancing in Ceph RGW
- Open-Source Load Balancer Options for Ceph RGW
- Why LVS TUN is Better for NVMe-Based Private AI S3 Storage
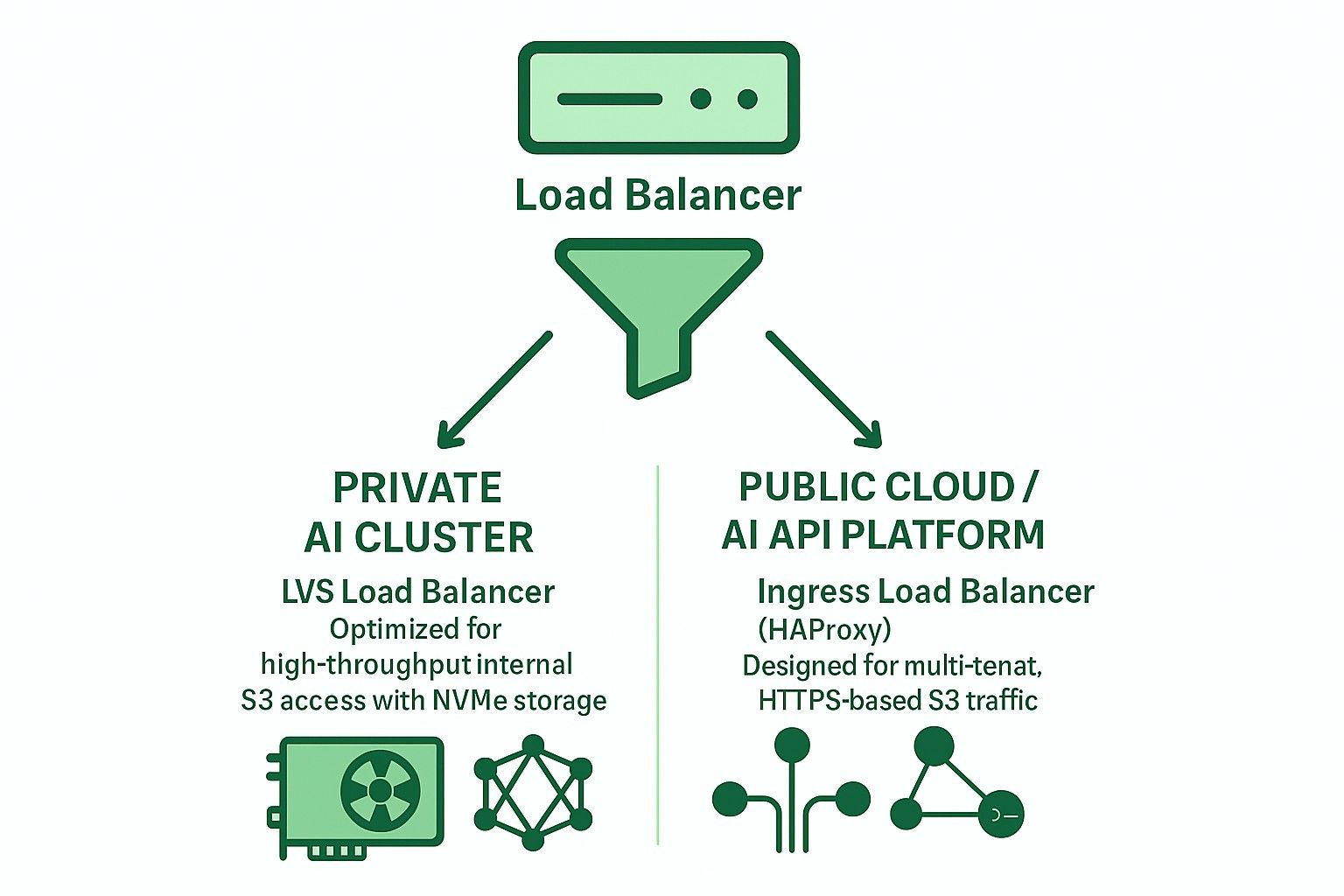
- Comparing LVS TUN vs Ingress for Private & Public Cloud AI Applications
- How Ambedded's UniVirStor Supports LVS Load Balancer for Ceph RGW
- Conclusion
Why AI Needs Scalable and Efficient Storage
Modern AI workloads require both fast access to training data and cost-effective long-term storage. S3 object storage, accessed over NVMe or HDD, provides a scalable backend for managing large datasets, checkpoints, and inference models.
- High-speed NVMe for training datasets and low-latency access
- Cost-efficient HDD for long-term storage and archives
Why S3 is Ideal for AI Workloads
S3-compatible storage is widely adopted in AI pipelines due to its RESTful API, scalability, and integration with ML frameworks. It supports:
- Dataset and model storage
- Checkpointing and artifact versioning
- Serving models to inference endpoints
- Integration with TensorFlow, PyTorch, MLFlow
Why Ceph RGW Is a Strong Fit for AI S3 Storage
Ceph RGW is an open-source, S3-compatible object storage service that offers high availability, strong consistency, and petabyte-scale scalability. Key features include:
- Supports scalability across hundreds of nodes
- Offers strong consistency and erasure coding for durability
- Provides integrated multi-site replication for hybrid cloud use cases
- Can be deployed on cost-effective commodity hardware
This makes Ceph RGW a powerful backend for AI-focused object storage at both the petabyte scale and performance-critical environments.
The Need for High-Availability Load Balancing in Ceph RGW
Ceph RGW is stateless, allowing horizontal scaling. However, to deliver:
- High availability
- Failover support
- Performance scalability
You need a front-end load balancer that can reliably and efficiently distribute incoming S3 requests (GET, PUT, DELETE) across multiple RGW instances.
Without proper load balancing, a single RGW node or front-end server may become a bottleneck or single point of failure.
Open-Source Load Balancer Options for Ceph RGW
Two primary architectures are commonly used with open-source load balancers:
- Ingress-Based (HAProxy + Keepalived + Multi-VIP + DNS RR)
- Layer 7 (HTTP) support
- Supports TLS termination, SNI-based multi-tenant routing
- Suitable for public cloud or multi-tenant deployments
- Slightly higher latency and requires careful tuning to avoid bottlenecks
- At larger deployment scales, multiple high-performance hardware servers are required to prevent HAProxy from becoming a bottleneck.
- LVS TUN + conntrackd + Weighted Least Connections (WLC)
- Layer 4 IP-in-IP tunneling
- High throughput and low CPU usage
- Bypasses balancer for return traffic
- Best for private, high-speed internal networks
Why LVS TUN is Better for NVMe-Based Private AI S3 Storage
For internal, NVMe-based AI training clusters, performance is the top priority:
- LVS TUN achieves near-line-rate bandwidth
- Does not terminate TLS, reducing CPU overhead
- conntrackd ensures seamless failover without client interruption
- No application-layer inspection reduces latency
Thus, LVS TUN is a better fit than HAProxy for high-speed internal AI object storage (e.g., GPU cluster training pipelines).
Comparing LVS TUN vs Ingress for Private & Public Cloud AI Applications
| Feature | Ingress (HAProxy) | LVS TUN + conntrackd |
|---|---|---|
| TLS termination | ✅ Yes | ❌ No |
| Multi-tenant routing | ✅ Yes | ❌ No |
| Throughput | ❌ Limited | ✅ Line-rate |
| Latency | ❌ Higher | ✅ Lower |
| Health checks | ✅ HTTP | ❌ TCP/ICMP |
| DNS integration | ✅ Required | ❌ Not needed |
| Ideal use case | Public cloud | Private AI/HPC |
How Ambedded's UniVirStor Supports LVS Load Balancer for Ceph RGW
UniVirStor offers native support for LVS TUN mode, including:
- Ansible-based automated setup
- High availability with keepalived and conntrackd
- Health check hooks and performance metrics
- Optimized routing for high-throughput S3 gateways
This makes UniVirStor ideal for customers building AI data lakes or GPU-based AI clusters that demand both performance and reliability from Ceph RGW.
Conclusion
Choosing the right load balancer architecture is essential for building a robust, scalable S3 storage backend for AI.
- For private AI clusters, use LVS TUN + conntrackd to maximize performance.
- For public-facing services or multi-tenant S3, use Ingress-based HAProxy for better flexibility and TLS handling.
Ambedded's UniVirStor helps you deploy both scenarios efficiently with production-grade tuning and high availability support.