Bilanciamento del carico di archiviazione S3 per AI con Ceph RGW
I carichi di lavoro dell'IA richiedono uno storage S3 scalabile e ad alta capacità di throughput per i dati di addestramento, i modelli e i risultati dell'inferenza. Ceph RGW offre un backend affidabile e compatibile con S3, ma le prestazioni dipendono fortemente dal bilanciamento del carico. Per i cluster AI privati che utilizzano NVMe, LVS TUN offre una larghezza di banda quasi a velocità di linea e bassa latenza. Il UniVirStor di Ambedded supporta nativamente LVS TUN con configurazione automatizzata e design HA, rendendolo ideale per ambienti di archiviazione AI critici per le prestazioni.
I seguenti punti chiave riassumono la necessità e la giustificazione per ciascuna scelta progettuale.
- Perché l'IA ha bisogno di archiviazione scalabile ed efficiente
- Perché S3 è ideale per i carichi di lavoro dell'IA
- Perché Ceph RGW è una scelta forte per l'archiviazione S3 dell'IA
- La necessità di bilanciamento del carico ad alta disponibilità in Ceph RGW
- Opzioni di bilanciamento del carico open-source per Ceph RGW
- Perché LVS TUN è migliore per lo storage privato AI S3 basato su NVMe
- Confronto tra LVS TUN e Ingress per applicazioni AI nel cloud privato e pubblico
- Come il UniVirStor di Ambedded supporta il bilanciatore di carico LVS per Ceph RGW
- Conclusione
Perché l'IA ha bisogno di archiviazione scalabile ed efficiente
I carichi di lavoro AI moderni richiedono sia un accesso rapido ai dati di addestramento che uno storage a lungo termine economico. Lo storage a oggetti S3, accessibile tramite NVMe o HDD, fornisce un backend scalabile per gestire grandi set di dati, checkpoint e modelli di inferenza.
- NVMe ad alta velocità per set di dati di addestramento e accesso a bassa latenza
- HDD economico per storage a lungo termine e archivi
Perché S3 è ideale per i carichi di lavoro dell'IA
Lo storage compatibile con S3 è ampiamente adottato nei pipeline AI grazie alla sua API RESTful, scalabilità e integrazione con framework ML. Supporta:
- Storage di dataset e modelli
- Checkpoint e versioni di artefatto
- Servire modelli a punti di inferenza
- Integrazione con Tensorflow, Pytorch, Mlflow
Perché Ceph RGW è una scelta forte per l'archiviazione S3 dell'IA
Ceph RGW è un servizio di archiviazione oggetti open-source, compatibile con S3, che offre alta disponibilità, forte coerenza e scalabilità a petabyte. Le caratteristiche principali includono:
- Supporta la scalabilità su centinaia di nodi
- Offre forte coerenza e codifica di cancellazione per la durabilità
- Fornisce replicazione multi-sito integrata per casi d'uso di cloud ibrido
- Può essere distribuito su hardware commodity a basso costo
Questo rende Ceph RGW un potente backend per l'archiviazione oggetti focalizzata sull'IA sia a scala petabyte che in ambienti critici per le prestazioni.
La necessità di bilanciamento del carico ad alta disponibilità in Ceph RGW
Ceph RGW è senza stato, consentendo la scalabilità orizzontale. Tuttavia, per fornire:
- Alta disponibilità
- Supporto al failover
- Scalabilità delle prestazioni
Hai bisogno di un bilanciatore di carico front-end che possa distribuire in modo affidabile ed efficiente le richieste S3 in arrivo (GET, PUT, DELETE) su più istanze RGW.
Senza un bilanciamento del carico adeguato, un singolo nodo RGW o server front-end può diventare un collo di bottiglia o un punto di guasto singolo.
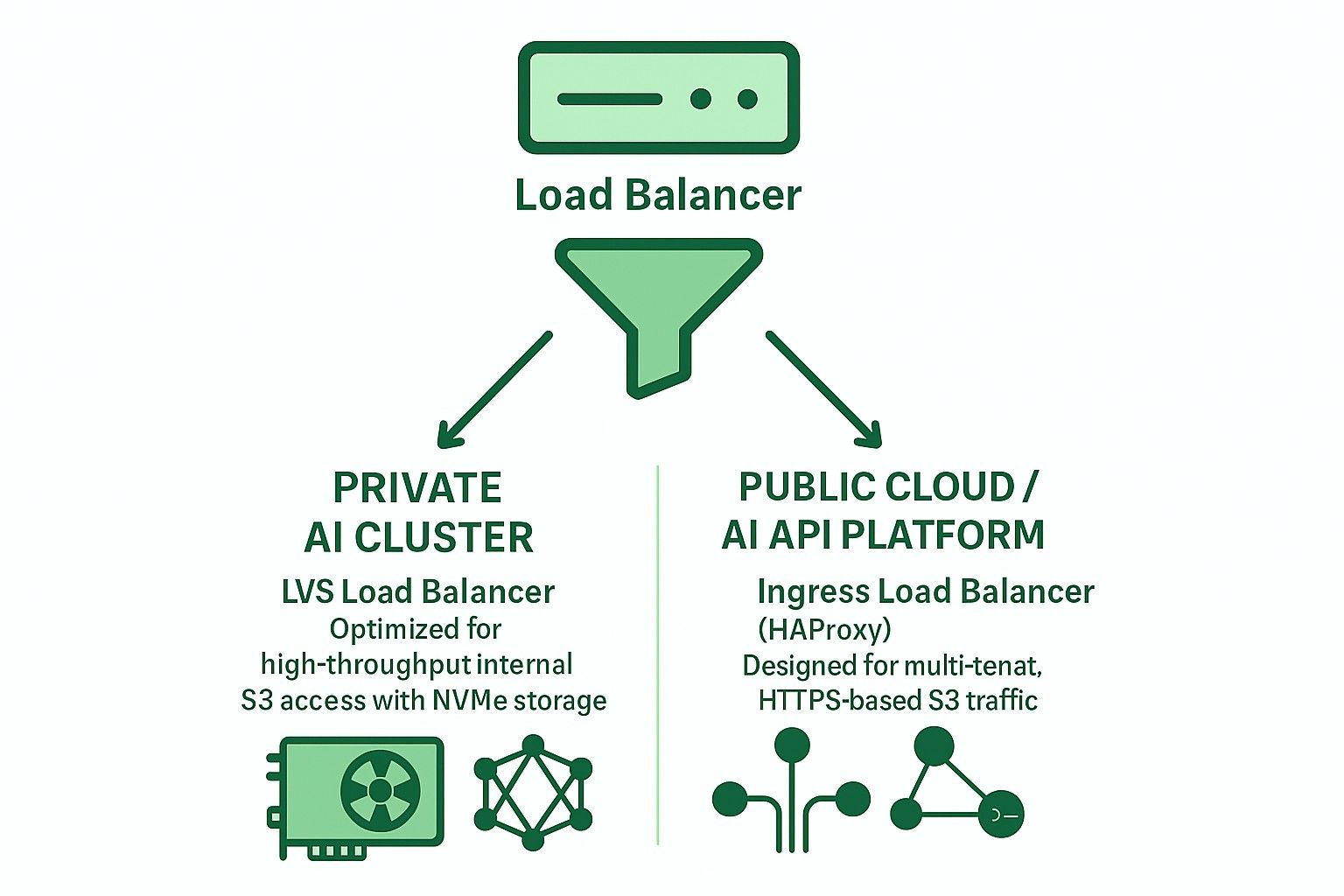
Opzioni di bilanciamento del carico open-source per Ceph RGW
Due architetture principali sono comunemente utilizzate con bilanciatori di carico open-source:
-
Basato su Ingress (HAProxy + Keepalived + Multi-VIP + DNS RR)
- Supporto Layer 7 (HTTP)
- Supporta la terminazione TLS, il routing multi-tenant basato su SNI
- Adatto per distribuzioni su cloud pubblico o multi-tenant
- Latenza leggermente più alta e richiede una messa a punto attenta per evitare colli di bottiglia
- A scale di distribuzione più grandi, sono necessari più server hardware ad alte prestazioni per evitare che HAProxy diventi un collo di bottiglia.
-
LVS TUN Conntrackd ponderato i minimi collegamenti (WLC)
- Tunnel IP-in-IP di livello 4
- Alto throughput e basso utilizzo della CPU
- Salta il bilanciatore per il traffico di ritorno
- Migliore per reti interne private ad alta velocità
Perché LVS TUN è migliore per lo storage privato AI S3 basato su NVMe
Per cluster di addestramento AI interni basati su NVMe, le prestazioni sono la massima priorità:
- LVS TUN raggiunge una larghezza di banda quasi a linea
- Non termina TLS, riducendo il sovraccarico della CPU
- conntrackd garantisce un failover senza soluzione di continuità senza interruzione per il cliente
- Nessuna ispezione a livello di applicazione riduce la latenza
Pertanto, LVS TUN è più adatto di HAProxy per lo storage interno ad alta velocità di oggetti AI (ad es., pipeline di addestramento di cluster GPU).
Confronto tra LVS TUN e Ingress per applicazioni AI nel cloud privato e pubblico
| Caratteristica | Ingress (Haproxy) | LVS Tun Conntrackd |
|---|---|---|
| Terminazione TLS | ✅ Sì | ❌ No |
| Routing multi-tenant | ✅ Sì | ❌ No |
| Throughput | ❌ Limitato | ✅ Velocità di linea |
| Latenza | ❌ Maggiore | ✅ Minore |
| Controlli di salute | ✅ http | ❌ TCP/ICMP |
| Integrazione DNS | ✅ Richiesto | ❌ Non necessario |
| Caso d'uso ideale | Cloud pubblico | AI/HPC privato |
Come il UniVirStor di Ambedded supporta il bilanciatore di carico LVS per Ceph RGW
UniVirStor offre supporto nativo per la modalità LVS TUN, inclusi:
- Impostazione automatizzata basata su Ansible
- Alta disponibilità con keepalived e conntrackd
- Hook di controllo della salute e metriche delle prestazioni
- Routing ottimizzato per gateway S3 ad alta capacità
Questo rende UniVirStor ideale per i clienti che costruiscono laghi di dati AI o cluster AI basati su GPU che richiedono sia prestazioni che affidabilità da Ceph RGW.
Conclusione
Scegliere l'architettura del bilanciatore di carico giusta è essenziale per costruire un backend di archiviazione S3 robusto e scalabile per l'IA.
- Per i cluster AI privati, utilizzare LVS TUN + conntrackd per massimizzare le prestazioni.
- Per i servizi esposti al pubblico o S3 multi-tenant, utilizzare HAProxy basato su Ingress per una migliore flessibilità e gestione del TLS.
Ambedded's UniVirStor ti aiuta a implementare entrambi gli scenari in modo efficiente con ottimizzazione di livello produzione e supporto per alta disponibilità.