Ceph RGW를 이용한 AI를 위한 S3 스토리지 로드 밸런싱
AI 작업 부하는 훈련 데이터, 모델 및 추론 출력을 위한 확장 가능하고 높은 처리량의 S3 스토리지가 필요합니다. Ceph RGW는 신뢰할 수 있는 S3 호환 백엔드를 제공하지만, 성능은 로드 밸런싱에 크게 의존합니다. NVMe를 사용하는 개인 AI 클러스터의 경우, LVS TUN은 거의 선형 속도의 대역폭과 낮은 지연 시간을 제공합니다. Ambedded의 UniVirStor는 자동 설정 및 HA 설계를 통해 LVS TUN을 기본적으로 지원하여 성능이 중요한 AI 스토리지 환경에 적합합니다.
다음의 주요 사항들은 각 설계 선택의 필요성과 정당성을 요약합니다.
- AI가 확장 가능하고 효율적인 스토리지를 필요로 하는 이유
- S3가 AI 작업에 이상적인 이유
- Ceph RGW가 AI S3 스토리지에 강력하게 적합한 이유
- Ceph RGW에서 고가용성 로드 밸런싱의 필요성
- Ceph RGW를 위한 오픈 소스 로드 밸런서 옵션
- 왜 LVS TUN이 NVMe 기반의 개인 AI S3 스토리지에 더 나은가?
- 개인 및 공공 클라우드 AI 애플리케이션을 위한 LVS TUN과 Ingress 비교
- Ambedded의 UniVirStor가 Ceph RGW를 위한 LVS 로드 밸런서를 지원하는 방법
- 결론
AI가 확장 가능하고 효율적인 스토리지를 필요로 하는 이유
현대 AI 작업 부하는 훈련 데이터에 대한 빠른 접근과 비용 효율적인 장기 저장소를 모두 요구합니다. NVMe 또는 HDD를 통해 접근하는 S3 객체 저장소는 대규모 데이터 세트, 체크포인트 및 추론 모델을 관리하기 위한 확장 가능한 백엔드를 제공합니다.
- 훈련 데이터 세트를 위한 고속 NVMe 및 저지연 접근
- 장기 저장 및 아카이브를 위한 비용 효율적인 HDD
S3가 AI 작업에 이상적인 이유
S3 호환 저장소는 RESTful API, 확장성 및 ML 프레임워크와의 통합 덕분에 AI 파이프라인에서 널리 채택되고 있습니다. 지원하는 기능은:
- 데이터 세트 및 모델 저장
- 체크포인팅 및 아티팩트 버전 관리
- 모델을 추론 엔드포인트에 제공하기
- Tensorflow, Pytorch, Mlflow와의 통합
Ceph RGW가 AI S3 스토리지에 강력하게 적합한 이유
Ceph RGW는 높은 가용성, 강력한 일관성 및 페타바이트 규모의 확장성을 제공하는 오픈 소스 S3 호환 객체 저장 서비스입니다. 주요 기능은 다음과 같습니다:
- 수백 개의 노드에 걸쳐 확장성 지원
- 내구성을 위한 강력한 일관성과 소거 코딩 제공
- 하이브리드 클라우드 사용 사례를 위한 통합된 다중 사이트 복제 제공
- 비용 효율적인 상용 하드웨어에 배포 가능
이로 인해 Ceph RGW는 페타바이트 규모와 성능이 중요한 환경 모두에서 AI 중심 객체 저장소를 위한 강력한 백엔드가 됩니다.
Ceph RGW에서 고가용성 로드 밸런싱의 필요성
Ceph RGW는 상태 비저장형으로 수평 확장을 허용합니다. 그러나 제공하기 위해:
- 높은 가용성
- 페일오버 지원
- 성능 확장성
신뢰성 있고 효율적으로 들어오는 S3 요청(GET, PUT, DELETE)을 여러 RGW 인스턴스에 분산할 수 있는 프론트엔드 로드 밸런서가 필요합니다.
적절한 로드 밸런싱이 없으면 단일 RGW 노드 또는 프론트엔드 서버가 병목 현상이나 단일 실패 지점이 될 수 있습니다.
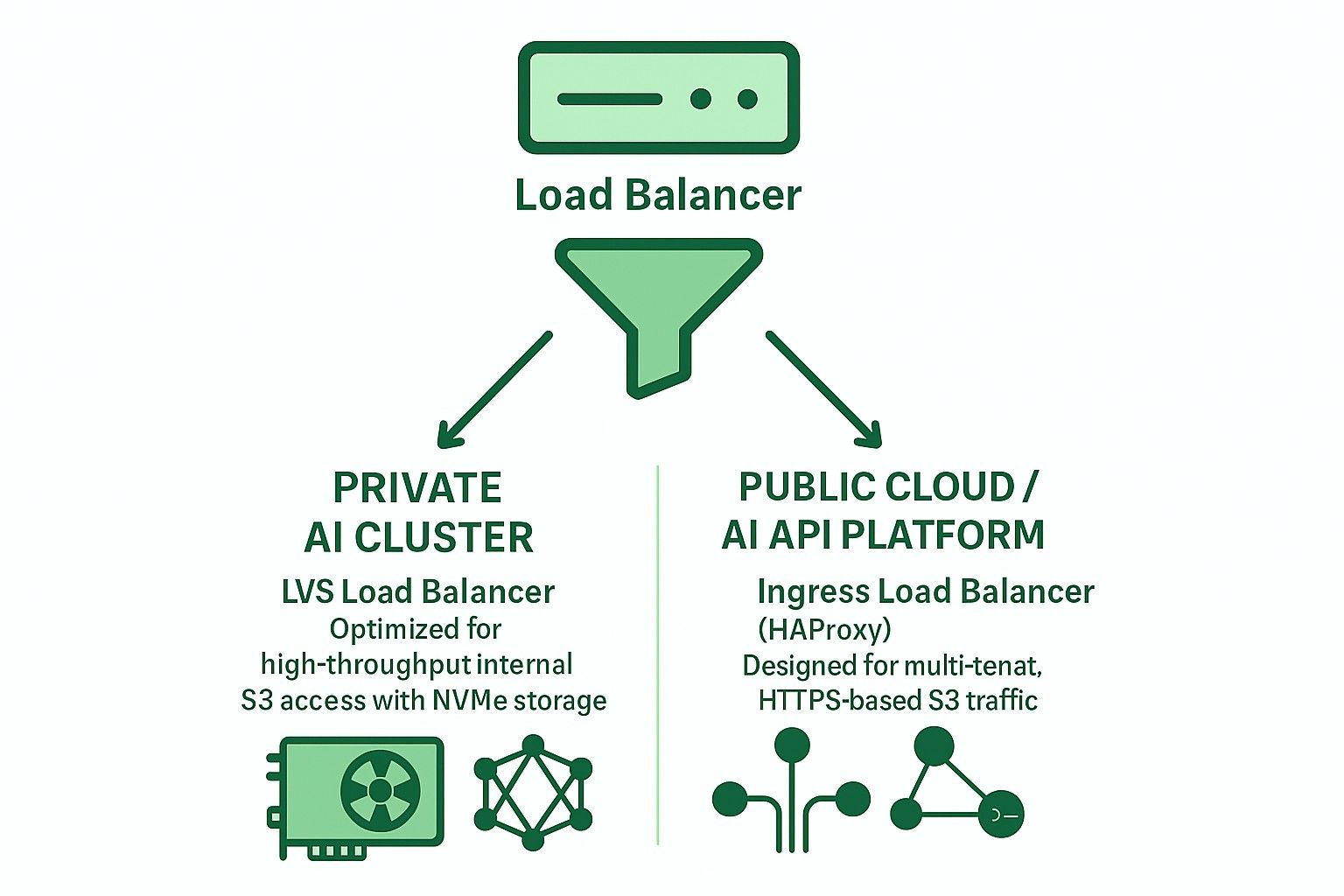
Ceph RGW를 위한 오픈 소스 로드 밸런서 옵션
오픈 소스 로드 밸런서와 함께 일반적으로 사용되는 두 가지 주요 아키텍처는 다음과 같습니다:
-
Ingress 기반 (HAProxy + Keepalived + Multi-VIP + DNS RR)
- 레이어 7 (HTTP) 지원
- TLS 종료, SNI 기반 다중 테넌트 라우팅 지원
- 공공 클라우드 또는 다중 테넌트 배포에 적합
- 약간 높은 대기 시간과 병목 현상을 피하기 위한 세심한 조정이 필요합니다.
- 더 큰 배포 규모에서는 HAProxy가 병목 현상이 되지 않도록 여러 고성능 하드웨어 서버가 필요합니다.
-
LVS TUN + conntrackd + 가중치 최소 연결(WLC)
- 4계층 IP-in-IP 터널링
- 높은 처리량과 낮은 CPU 사용량
- 반환 트래픽을 위해 로드 밸런서를 우회합니다.
- 개인용 고속 내부 네트워크에 가장 적합합니다.
왜 LVS TUN이 NVMe 기반의 개인 AI S3 스토리지에 더 나은가?
내부 NVMe 기반 AI 훈련 클러스터의 경우 성능이 최우선입니다:
- LVS TUN은 거의 선형 속도의 대역폭을 달성합니다.
- TLS를 종료하지 않아 CPU 오버헤드를 줄입니다.
- conntrackd는 클라이언트 중단 없이 원활한 장애 조치를 보장합니다.
- 애플리케이션 계층 검사가 지연 시간을 줄입니다.
따라서 LVS TUN은 고속 내부 AI 객체 저장소(예: GPU 클러스터 훈련 파이프라인)에 HAProxy보다 더 적합합니다.
개인 및 공공 클라우드 AI 애플리케이션을 위한 LVS TUN과 Ingress 비교
| 기능 | 유입 (하프 렉시) | LVS Tun Conntrackd |
|---|---|---|
| TLS 종료 | ✅ 예 | ❌ 아니오 |
| 다중 테넌트 라우팅 | ✅ 예 | ❌ 아니오 |
| 처리량 | ❌ 제한됨 | ✅ 라인 속도 |
| 지연 시간 | ❌ 더 높음 | ✅ 더 낮음 |
| 상태 검사 | ✅ HTTP | ❌ TCP/ICMP |
| DNS 통합 | ✅ 필요함 | ❌ 필요하지 않음 |
| 이상적인 사용 사례 | 퍼블릭 클라우드 | 프라이빗 AI/HPC |
Ambedded의 UniVirStor가 Ceph RGW를 위한 LVS 로드 밸런서를 지원하는 방법
UniVirStor는 다음을 포함하여 LVS TUN 모드에 대한 기본 지원을 제공합니다:
- Ansible 기반 자동 설정
- keepalived 및 conntrackd를 통한 고가용성
- 헬스 체크 훅 및 성능 메트릭
- 고처리량 S3 게이트웨이를 위한 최적화된 라우팅
이로 인해 UniVirStor는 성능과 신뢰성을 모두 요구하는 AI 데이터 레이크 또는 GPU 기반 AI 클러스터를 구축하는 고객에게 이상적입니다.
결론
올바른 로드 밸런서 아키텍처를 선택하는 것은 AI를 위한 강력하고 확장 가능한 S3 스토리지 백엔드를 구축하는 데 필수적입니다.
- 개인 AI 클러스터의 경우, 성능을 극대화하기 위해 LVS TUN + conntrackd를 사용하세요.
- 공개 서비스나 다중 테넌트 S3의 경우, 더 나은 유연성과 TLS 처리를 위해 Ingress 기반 HAProxy를 사용하세요.
Ambedded의 UniVirStor는 생산 수준의 조정 및 고가용성 지원으로 두 가지 시나리오를 효율적으로 배포하는 데 도움을 줍니다.