Équilibrage de charge de stockage S3 pour l'IA avec Ceph RGW
Les charges de travail d'IA nécessitent un stockage S3 évolutif et à haut débit pour les données d'entraînement, les modèles et les résultats d'inférence. Ceph RGW offre un backend fiable et compatible S3, mais les performances dépendent fortement de l'équilibrage de charge. Pour les clusters d'IA privés utilisant NVMe, LVS TUN offre une bande passante proche du taux de ligne et une faible latence. Le UniVirStor de Ambedded prend en charge nativement LVS TUN avec une configuration automatisée et un design HA, ce qui le rend idéal pour les environnements de stockage AI critiques en termes de performance.
Les points clés suivants résument le besoin et la justification de chaque choix de conception.
- Pourquoi l'IA a besoin d'un stockage évolutif et efficace
- Pourquoi S3 est idéal pour les charges de travail d'IA
- Pourquoi Ceph RGW est un choix solide pour le stockage S3 d'IA
- Le besoin d'un équilibrage de charge à haute disponibilité dans Ceph RGW
- Options d'équilibreur de charge open-source pour Ceph RGW
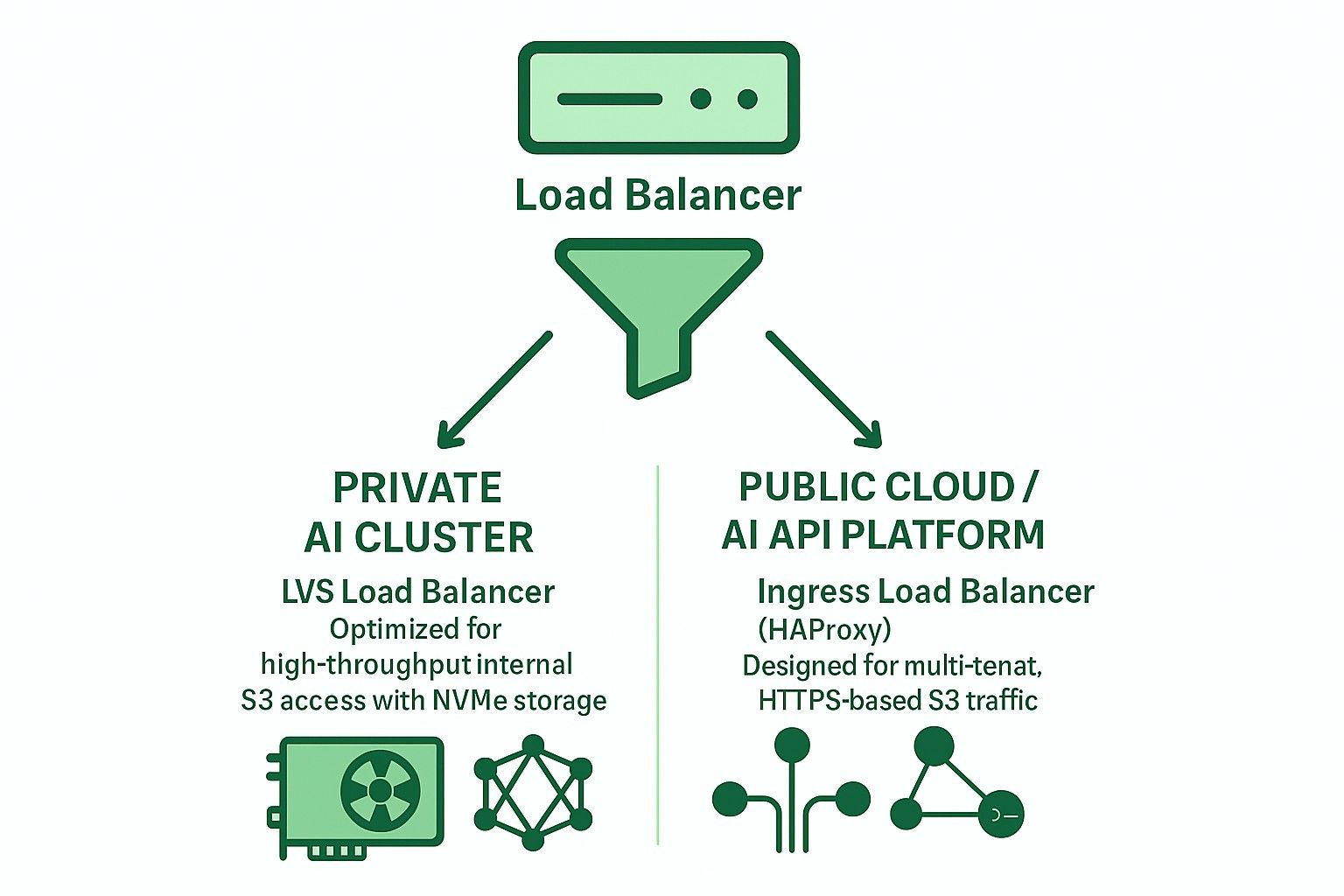
- Pourquoi LVS TUN est meilleur pour le stockage privé AI S3 basé sur NVMe
- Comparaison entre LVS TUN et Ingress pour les applications AI dans le cloud privé et public
- Comment le UniVirStor d'Ambedded prend en charge le répartiteur de charge LVS pour Ceph RGW
- Conclusion
Pourquoi l'IA a besoin d'un stockage évolutif et efficace
Les charges de travail modernes en IA nécessitent un accès rapide aux données d'entraînement et un stockage à long terme rentable. Le stockage d'objets S3, accessible via NVMe ou HDD, fournit un backend évolutif pour gérer de grands ensembles de données, des points de contrôle et des modèles d'inférence.
- NVMe à haute vitesse pour les ensembles de données d'entraînement et accès à faible latence
- HDD rentable pour le stockage à long terme et les archives
Pourquoi S3 est idéal pour les charges de travail d'IA
Le stockage compatible S3 est largement adopté dans les pipelines AI en raison de son API RESTful, de sa scalabilité et de son intégration avec les frameworks ML. Il prend en charge :
- Stockage d'ensembles de données et de modèles
- Point de contrôle et versionnage des artefacts
- Servir des modèles aux points de terminaison d'inférence
- Intégration avec TensorFlow, Pytorch, Mlflow
Pourquoi Ceph RGW est un choix solide pour le stockage S3 d'IA
Ceph RGW est un service de stockage d'objets open-source, compatible S3, qui offre une haute disponibilité, une forte cohérence et une évolutivité à l'échelle des pétaoctets. Les caractéristiques clés incluent :
- Prend en charge l'évolutivité sur des centaines de nœuds
- Offre une forte cohérence et un codage de suppression pour la durabilité
- Fournit une réplication multi-sites intégrée pour des cas d'utilisation en cloud hybride
- Peut être déployé sur du matériel standard rentable
Cela fait de Ceph RGW un backend puissant pour le stockage d'objets axé sur l'IA, tant à l'échelle des pétaoctets que dans des environnements critiques en termes de performance.
Le besoin d'un équilibrage de charge à haute disponibilité dans Ceph RGW
Ceph RGW est sans état, permettant une mise à l'échelle horizontale. Cependant, pour offrir :
- Haute disponibilité
- Support de basculement
- Scalabilité des performances
Vous avez besoin d'un équilibreur de charge frontal qui peut distribuer de manière fiable et efficace les requêtes S3 entrantes (GET, PUT, DELETE) sur plusieurs instances RGW.
Sans un équilibrage de charge approprié, un seul nœud RGW ou serveur frontal peut devenir un goulot d'étranglement ou un point de défaillance unique.
Options d'équilibreur de charge open-source pour Ceph RGW
Deux architectures principales sont couramment utilisées avec des équilibreurs de charge open-source :
-
Basé sur l'Ingress (HAProxy + Keepalived + Multi-VIP + DNS RR)
- Support de la couche 7 (HTTP)
- Prend en charge la terminaison TLS, le routage multi-locataire basé sur SNI
- Convient aux déploiements dans le cloud public ou multi-locataire
- Latence légèrement plus élevée et nécessite un réglage minutieux pour éviter les goulots d'étranglement
- À des échelles de déploiement plus importantes, plusieurs serveurs matériels haute performance sont nécessaires pour empêcher HAProxy de devenir un goulot d'étranglement.
-
LVS TUN + conntrackd + Connexions les Moins Chargées Pondérées (WLC)
- Tunneling IP-in-IP de couche 4
- Haut débit et faible utilisation du CPU
- Contourne le répartiteur pour le trafic de retour
- Meilleur pour les réseaux internes privés à haute vitesse
Pourquoi LVS TUN est meilleur pour le stockage privé AI S3 basé sur NVMe
Pour les clusters d'entraînement AI internes basés sur NVMe, la performance est la priorité absolue :
- LVS TUN atteint une bande passante proche du taux de ligne
- Ne termine pas le TLS, réduisant ainsi la surcharge CPU
- conntrackd assure un basculement transparent sans interruption pour le client
- Aucune inspection au niveau de l'application ne réduit la latence
Ainsi, LVS TUN est mieux adapté que HAProxy pour le stockage d'objets AI interne à haute vitesse (par exemple, les pipelines d'entraînement de clusters GPU).
Comparaison entre LVS TUN et Ingress pour les applications AI dans le cloud privé et public
| Fonctionnalité | Entrave (haproxy) | LVS Tun Conntrackd |
|---|---|---|
| Terminaison TLS | ✅ Oui | ❌ Non |
| Routage multi-locataire | ✅ Oui | ❌ Non |
| Débit | ❌ Limité | ✅ Taux de ligne |
| Latence | ❌ Plus élevé | ✅ Plus bas |
| Vérifications de santé | ✅ http | ❌ TCP/ICMP |
| Intégration DNS | ✅ Requis | ❌ Pas nécessaire |
| Cas d'utilisation idéal | Cloud public | IA/HPC privé |
Comment le UniVirStor d'Ambedded prend en charge le répartiteur de charge LVS pour Ceph RGW
UniVirStor offre un support natif pour le mode LVS TUN, y compris :
- Configuration automatisée basée sur Ansible
- Haute disponibilité avec keepalived et conntrackd
- Hooks de vérification de santé et métriques de performance
- Routage optimisé pour des passerelles S3 à haut débit
Cela rend UniVirStor idéal pour les clients construisant des lacs de données IA ou des clusters IA basés sur GPU qui exigent à la fois performance et fiabilité de Ceph RGW.
Conclusion
Choisir la bonne architecture de répartiteur de charge est essentiel pour construire un backend de stockage S3 robuste et évolutif pour l'IA.
- Pour les clusters d'IA privés, utilisez LVS TUN + conntrackd pour maximiser les performances.
- Pour les services accessibles au public ou S3 multi-locataires, utilisez HAProxy basé sur Ingress pour une meilleure flexibilité et gestion de TLS.
Le UniVirStor dAmbedded vous aide à déployer efficacement les deux scénarios avec un réglage de qualité production et un support de haute disponibilité.