Równoważenie obciążenia pamięci S3 dla AI z Ceph RGW
Obciążenia AI wymagają skalowalnego, o wysokiej przepustowości magazynu S3 do danych treningowych, modeli i wyników wnioskowania. Ceph RGW oferuje niezawodny, zgodny z S3 backend, ale wydajność w dużej mierze zależy od równoważenia obciążenia. Dla prywatnych klastrów AI korzystających z NVMe, LVS TUN zapewnia niemal pełną przepustowość i niskie opóźnienia. UniVirStor 'a Ambedded natywnie wspiera LVS TUN z automatyczną konfiguracją i projektowaniem HA, co czyni go idealnym dla środowisk pamięci masowej AI krytycznych dla wydajności.
Poniższe kluczowe punkty podsumowują potrzebę i uzasadnienie dla każdego wyboru projektowego.
- Dlaczego AI potrzebuje skalowalnej i wydajnej pamięci masowej
- Dlaczego S3 jest idealne dla obciążeń AI
- Dlaczego Ceph RGW jest doskonałym rozwiązaniem dla pamięci masowej AI S3
- Potrzeba wysokodostępnego równoważenia obciążenia w Ceph RGW
- Opcje równoważenia obciążenia open-source dla Ceph RGW
- Dlaczego LVS TUN jest lepszy dla prywatnego przechowywania AI S3 opartego na NVMe
- Porównanie LVS TUN vs Ingress dla prywatnych i publicznych aplikacji AI w chmurze
- Jak UniVirStor Ambedded wspiera LVS Load Balancer dla Ceph RGW
- Podsumowanie
Dlaczego AI potrzebuje skalowalnej i wydajnej pamięci masowej
Nowoczesne obciążenia AI wymagają zarówno szybkiego dostępu do danych treningowych, jak i opłacalnego długoterminowego przechowywania. Przechowywanie obiektów S3, dostępne przez NVMe lub HDD, zapewnia skalowalny backend do zarządzania dużymi zbiorami danych, punktami kontrolnymi i modelami inferencyjnymi.
- Szybkie NVMe dla zbiorów danych treningowych i niskolatencyjny dostęp
- Opłacalne HDD dla długoterminowego przechowywania i archiwów
Dlaczego S3 jest idealne dla obciążeń AI
Przechowywanie zgodne z S3 jest szeroko stosowane w potokach AI z powodu swojego RESTful API, skalowalności i integracji z frameworkami ML. Wspiera:
- Przechowywanie zbiorów danych i modeli
- Punktowanie kontrolne i wersjonowanie artefaktów
- Serwowanie modeli do punktów końcowych inferencji
- Integracja z TensorFlow, Pytorch, Mlflow
Dlaczego Ceph RGW jest doskonałym rozwiązaniem dla pamięci masowej AI S3
Ceph RGW to otwartoźródłowa usługa przechowywania obiektów zgodna z S3, która oferuje wysoką dostępność, silną spójność i skalowalność na poziomie petabajtów. Kluczowe cechy to:
- Obsługuje skalowalność w setkach węzłów
- Oferuje silną spójność i kodowanie usuwania dla trwałości
- Zapewnia zintegrowaną replikację wielostanowiskową dla przypadków użycia w chmurze hybrydowej
- Może być wdrażany na opłacalnym sprzęcie konsumenckim
To sprawia, że Ceph RGW jest potężnym zapleczem dla przechowywania obiektów skoncentrowanego na AI zarówno na poziomie petabajtów, jak i w środowiskach krytycznych dla wydajności.
Potrzeba wysokodostępnego równoważenia obciążenia w Ceph RGW
Ceph RGW jest bezstanowy, co pozwala na poziomą skalowalność. Jednak aby dostarczyć:
- Wysoką dostępność
- Wsparcie awaryjne
- Skalowalność wydajności
Potrzebujesz zewnętrznego balansu obciążenia, który może niezawodnie i efektywnie rozdzielać przychodzące żądania S3 (GET, PUT, DELETE) pomiędzy wieloma instancjami RGW.
Bez odpowiedniego rozkładu obciążenia, pojedynczy węzeł RGW lub serwer front-end może stać się wąskim gardłem lub pojedynczym punktem awarii.
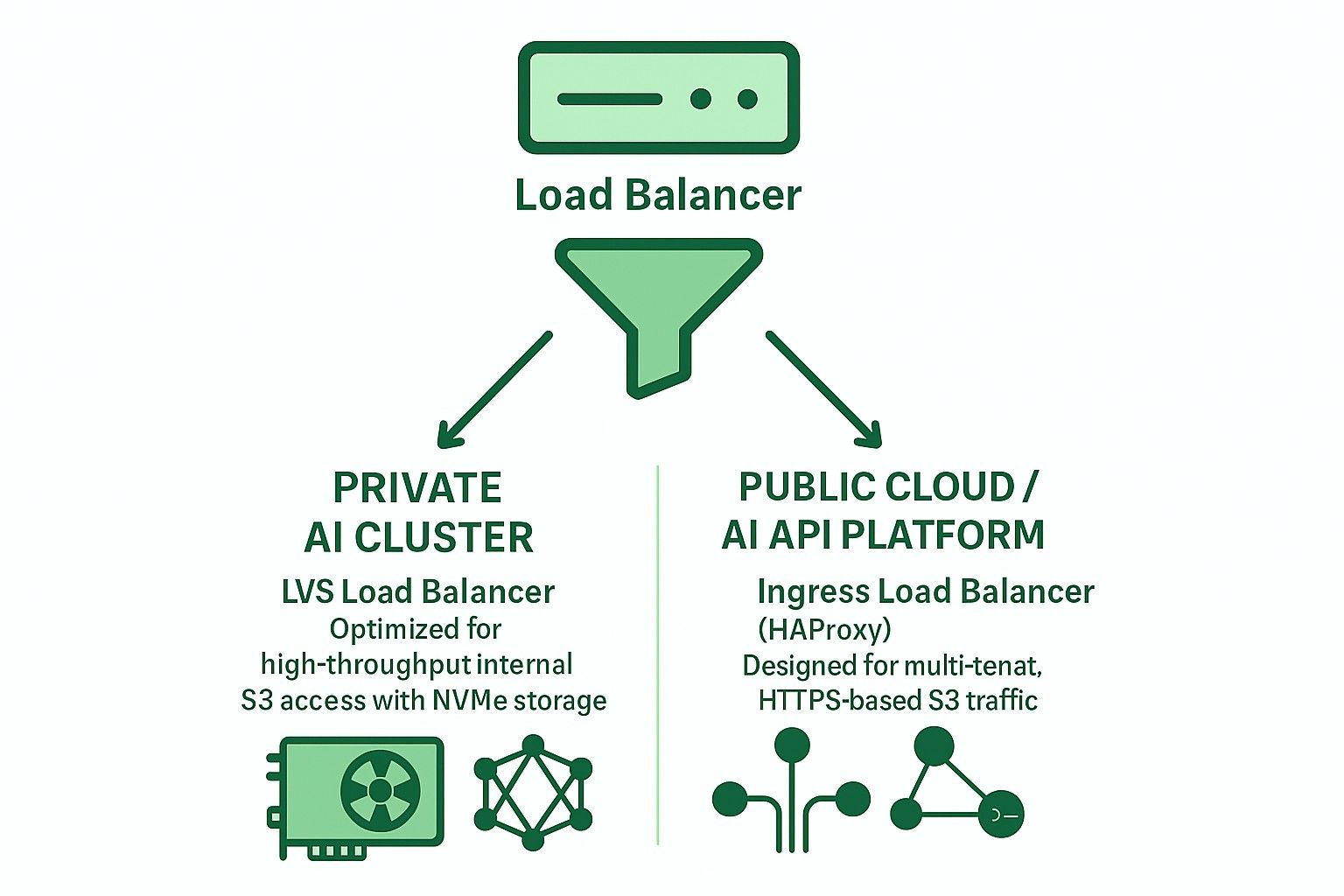
Opcje równoważenia obciążenia open-source dla Ceph RGW
Dwie podstawowe architektury są powszechnie używane z otwartoźródłowymi balancerami obciążenia:
-
Oparte na Ingress (HAProxy + Keepalived + Multi-VIP + DNS RR)
- Wsparcie warstwy 7 (HTTP)
- Obsługuje zakończenie TLS, routing wielodostępowy oparty na SNI
- Odpowiednie dla publicznych chmur lub wdrożeń wielodostępnych
- Nieco wyższe opóźnienie i wymaga starannego dostrojenia, aby uniknąć wąskich gardeł
- Przy większych skalach wdrożenia wymagane są wiele wydajnych serwerów sprzętowych, aby zapobiec staniu się HAProxy wąskim gardłem.
-
LVS TUN + conntrackd + Ważone Najmniejsze Połączenia (WLC)
- Tunelowanie IP w IP na warstwie 4
- Wysoka przepustowość i niskie zużycie CPU
- Omija balancer dla ruchu powrotnego
- Najlepsze dla prywatnych, szybkich sieci wewnętrznych
Dlaczego LVS TUN jest lepszy dla prywatnego przechowywania AI S3 opartego na NVMe
Dla wewnętrznych klastrów szkoleniowych AI opartych na NVMe, wydajność jest najwyższym priorytetem:
- LVS TUN osiąga przepustowość bliską prędkości linii
- Nie kończy TLS, co zmniejsza obciążenie CPU
- conntrackd zapewnia bezproblemowe przełączanie awaryjne bez przerywania klienta
- Brak inspekcji na poziomie aplikacji zmniejsza opóźnienia
Dlatego LVS TUN jest lepszym rozwiązaniem niż HAProxy dla szybkiego wewnętrznego przechowywania obiektów AI (np. pipeline'ów treningowych klastrów GPU).
Porównanie LVS TUN vs Ingress dla prywatnych i publicznych aplikacji AI w chmurze
| Funkcja | Wnikanie (Haproxy) | LVS TUN CONTRACKD |
|---|---|---|
| Zakończenie TLS | ✅ Tak | ❌ Nie |
| Routing wielodostępowy | ✅ Tak | ❌ Nie |
| Przepustowość | ❌ Ograniczone | ✅ Stawka linii |
| Opóźnienie | ❌ Wyższe | ✅ Niższe |
| Kontrole stanu | ✅ Http | ❌ TCP/ICMP |
| Integracja DNS | ✅ Wymagane | ❌ Niepotrzebne |
| Idealny przypadek użycia | Publiczna chmura | Prywatna AI/HPC |
Jak UniVirStor Ambedded wspiera LVS Load Balancer dla Ceph RGW
UniVirStor oferuje natywne wsparcie dla trybu LVS TUN, w tym:
- Automatyczna konfiguracja oparta na Ansible
- Wysoka dostępność z keepalived i conntrackd
- Hooki do sprawdzania stanu i metryki wydajności
- Optymalizowane routowanie dla bramek S3 o wysokiej przepustowości
To sprawia, że UniVirStor jest idealny dla klientów budujących jeziora danych AI lub klastry AI oparte na GPU, które wymagają zarówno wydajności, jak i niezawodności od Ceph RGW.
Podsumowanie
Wybór odpowiedniej architektury load balancera jest kluczowy dla budowy solidnego, skalowalnego backendu S3 dla AI.
- Dla prywatnych klastrów AI użyj LVS TUN + conntrackd, aby zmaksymalizować wydajność.
- Dla usług skierowanych do publiczności lub wielodostępnego S3 użyj HAProxy opartego na Ingress, aby uzyskać lepszą elastyczność i obsługę TLS.
Ambedded UniVirStor pomaga efektywnie wdrożyć oba scenariusze z tuningiem na poziomie produkcyjnym i wsparciem dla wysokiej dostępności.