Ceph RGWを使用したAI向けS3ストレージロードバランシング
AIワークロードには、トレーニングデータ、モデル、および推論出力のためのスケーラブルで高スループットのS3ストレージが必要です。 Ceph RGWは信頼性の高いS3互換のバックエンドを提供しますが、パフォーマンスは負荷分散に大きく依存します。 NVMeを使用したプライベートAIクラスターでは、LVS TUNがほぼラインレートの帯域幅と低遅延を提供します。 AmbeddedのUniVirStorは、LVS TUNをネイティブにサポートし、自動セットアップとHA設計を備えているため、パフォーマンスが重要なAIストレージ環境に最適です。
以下の重要なポイントは、各設計選択の必要性と正当性を要約しています。
- なぜAIはスケーラブルで効率的なストレージを必要とするのか
- なぜS3はAIワークロードに理想的なのか
- なぜCeph RGWはAI S3ストレージに強く適合するのか
- Ceph RGWにおける高可用性ロードバランシングの必要性
- Ceph RGWのためのオープンソースロードバランサーの選択肢
- なぜLVS TUNがNVMeベースのプライベートAI S3ストレージに優れているのか
- プライベートおよびパブリッククラウドAIアプリケーションのためのLVS TUNとIngressの比較
- AmbeddedのUniVirStorがCeph RGWのためにLVSロードバランサーをサポートする方法
- 結論
なぜAIはスケーラブルで効率的なストレージを必要とするのか
現代のAIワークロードは、トレーニングデータへの迅速なアクセスとコスト効率の良い長期ストレージの両方を必要とします。NVMeまたはHDDを介してアクセスされるS3オブジェクトストレージは、大規模なデータセット、チェックポイント、および推論モデルを管理するためのスケーラブルなバックエンドを提供します。
- トレーニングデータセットのための高速NVMeと低遅延アクセス
- 長期ストレージとアーカイブのためのコスト効率の良いHDD
なぜS3はAIワークロードに理想的なのか
S3互換ストレージは、そのRESTful API、スケーラビリティ、およびMLフレームワークとの統合により、AIパイプラインで広く採用されています。サポート内容は:
- データセットとモデルのストレージ
- チェックポイントとアーティファクトのバージョン管理
- 推論エンドポイントへのモデル提供
- Tensorflow、Pytorch、Mlflowとの統合
なぜCeph RGWはAI S3ストレージに強く適合するのか
Ceph RGWはオープンソースのS3互換オブジェクトストレージサービスで、高可用性、強い整合性、ペタバイト規模のスケーラビリティを提供します。主な機能は次のとおりです:
- 数百のノードにわたるスケーラビリティをサポート
- 耐久性のための強い整合性と消失コーディングを提供
- ハイブリッドクラウドユースケースのための統合されたマルチサイトレプリケーションを提供
- コスト効果の高い汎用ハードウェアに展開可能
これにより、Ceph RGWはペタバイト規模およびパフォーマンスが重要な環境におけるAI向けオブジェクトストレージの強力なバックエンドとなります。
Ceph RGWにおける高可用性ロードバランシングの必要性
Ceph RGWはステートレスであり、水平スケーリングを可能にします。ただし、提供するためには:
- 高可用性
- フェイルオーバーサポート
- パフォーマンスのスケーラビリティ
信頼性が高く効率的にS3リクエスト(GET、PUT、DELETE)を複数のRGWインスタンスに分配できるフロントエンドロードバランサーが必要です。
適切なロードバランシングがないと、単一のRGWノードまたはフロントエンドサーバーがボトルネックまたは単一障害点になる可能性があります。
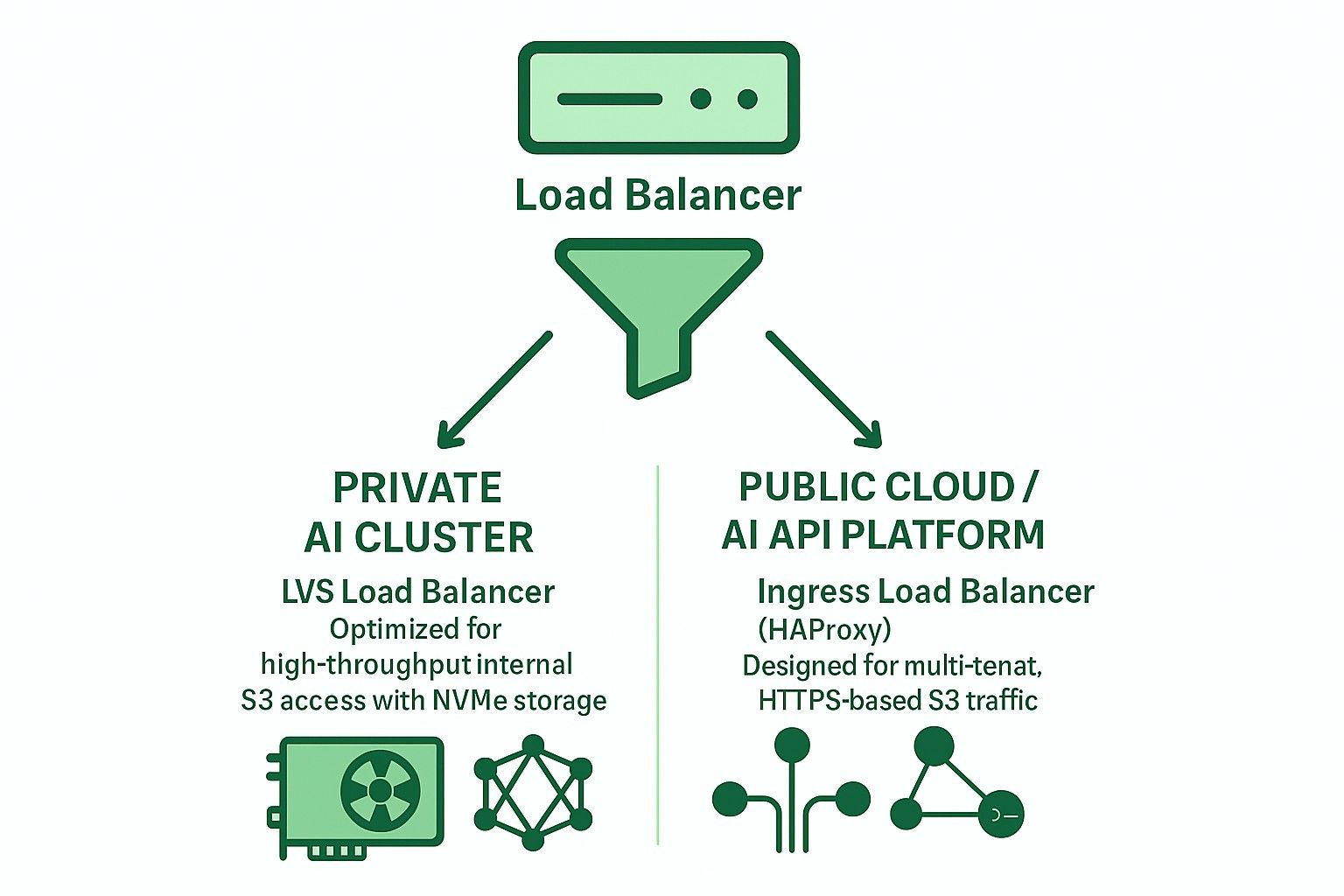
Ceph RGWのためのオープンソースロードバランサーの選択肢
オープンソースのロードバランサーで一般的に使用される2つの主要なアーキテクチャは次のとおりです:
-
イングレスベース(HAProxy + Keepalived + Multi-VIP + DNS RR)
- レイヤー7(HTTP)サポート
- TLS終端、SNIベースのマルチテナントルーティングをサポート
- パブリッククラウドまたはマルチテナントデプロイメントに適しています
- わずかに高いレイテンシーがあり、ボトルネックを避けるために慎重な調整が必要です
- 大規模な展開では、HAProxyがボトルネックにならないようにするために、複数の高性能ハードウェアサーバーが必要です。
-
LVS TUN + conntrackd + 重み付き最小接続数 (WLC)
- レイヤー4 IP-in-IP トンネリング
- 高スループットと低CPU使用率
- 戻りトラフィックのためにバランサーをバイパスします
- プライベートで高速な内部ネットワークに最適です
なぜLVS TUNがNVMeベースのプライベートAI S3ストレージに優れているのか
内部のNVMeベースのAIトレーニングクラスターでは、パフォーマンスが最優先です:
- LVS TUNはほぼラインレートの帯域幅を実現します
- TLSを終了しないため、CPUオーバーヘッドが削減されます
- conntrackdはクライアントの中断なしにシームレスなフェイルオーバーを保証します
- アプリケーション層の検査を行わないことでレイテンシが低減します。
したがって、LVS TUNはHAProxyよりも高速な内部AIオブジェクトストレージ(例:GPUクラスターのトレーニングパイプライン)に適しています。
プライベートおよびパブリッククラウドAIアプリケーションのためのLVS TUNとIngressの比較
| 機能 | インバウンド(HAProxy) | LVS Tun Conntrackd |
|---|---|---|
| TLS終端 | ✅ はい | ❌ いいえ |
| マルチテナントルーティング | ✅ はい | ❌ いいえ |
| スループット | ❌ 制限あり | ✅ ラインレート |
| レイテンシ | ❌ 高い | ✅ 低い |
| ヘルスチェック | http | ❌ TCP/ICMP |
| DNS統合 | ✅ 必須 | ❌ 不要 |
| 理想的な使用ケース | パブリッククラウド | プライベートAI/HPC |
AmbeddedのUniVirStorがCeph RGWのためにLVSロードバランサーをサポートする方法
UniVirStorは、次のLVS TUNモードのネイティブサポートを提供します:
- Ansibleベースの自動セットアップ
- keepalivedとconntrackdによる高可用性
- ヘルスチェックフックとパフォーマンスメトリクス
- 高スループットS3ゲートウェイのための最適化されたルーティング
これにより、UniVirStorは、Ceph RGWからのパフォーマンスと信頼性の両方を要求するAIデータレイクやGPUベースのAIクラスターを構築する顧客にとって理想的です。
結論
適切なロードバランサーアーキテクチャを選択することは、AIのための堅牢でスケーラブルなS3ストレージバックエンドを構築するために不可欠です。
- プライベートAIクラスターには、パフォーマンスを最大化するためにLVS TUN + conntrackdを使用してください。
- 公開サービスやマルチテナントS3には、柔軟性とTLS処理を向上させるためにIngressベースのHAProxyを使用してください。
AmbeddedのUniVirStorは、プロダクショングレードの調整と高可用性サポートを備えた両方のシナリオを効率的に展開するのに役立ちます。