Load Balancing Penyimpanan S3 untuk AI dengan Ceph RGW
Beban kerja AI memerlukan penyimpanan S3 yang dapat diskalakan dan memiliki throughput tinggi untuk data pelatihan, model, dan output inferensi. Ceph RGW menawarkan backend yang andal dan kompatibel dengan S3, tetapi kinerja sangat bergantung pada penyeimbangan beban. Untuk kluster AI pribadi yang menggunakan NVMe, LVS TUN menyediakan bandwidth mendekati laju garis dan latensi rendah. UniVirStor dari Ambedded secara native mendukung LVS TUN dengan pengaturan otomatis dan desain HA, menjadikannya ideal untuk lingkungan penyimpanan AI yang kritis terhadap kinerja.
Poin-poin kunci berikut merangkum kebutuhan dan justifikasi untuk setiap pilihan desain.
- Mengapa AI Membutuhkan Penyimpanan yang Skalabel dan Efisien
- Mengapa S3 Ideal untuk Beban Kerja AI
- Mengapa Ceph RGW Sangat Cocok untuk Penyimpanan AI S3
- Kebutuhan untuk Penyeimbangan Beban yang Tinggi Ketersediaan di Ceph RGW
- Opsi Penyeimbang Beban Sumber Terbuka untuk Ceph RGW
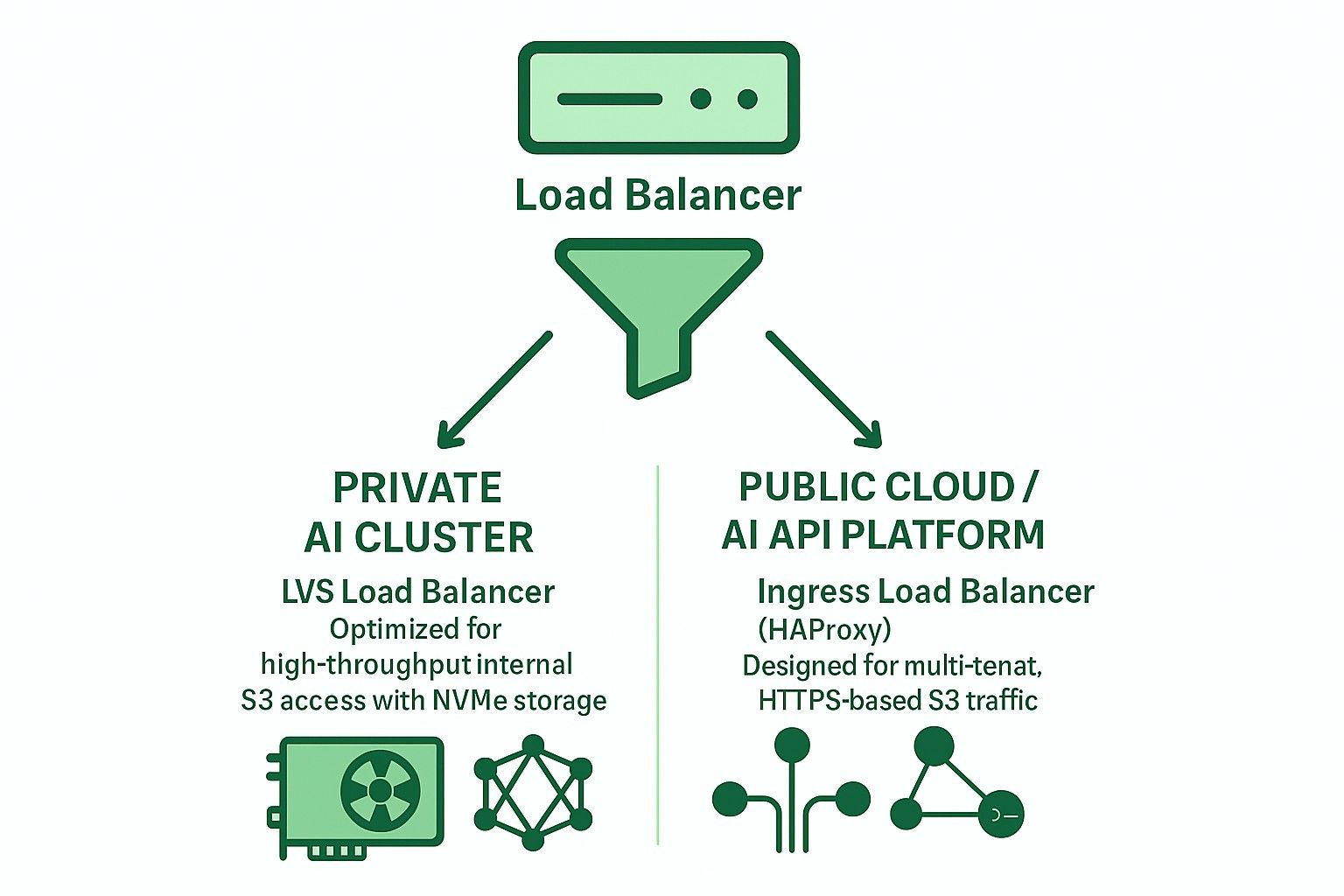
- Mengapa LVS TUN Lebih Baik untuk Penyimpanan AI S3 Pribadi Berbasis NVMe
- Membandingkan LVS Tun vs Ingress untuk pribadi & amp; Aplikasi AI Cloud Publik
- Bagaimana UniVirStor Ambedded Mendukung LVS Load Balancer untuk Ceph RGW
- Kesimpulan
Mengapa AI Membutuhkan Penyimpanan yang Skalabel dan Efisien
Beban kerja AI modern memerlukan akses cepat ke data pelatihan dan penyimpanan jangka panjang yang hemat biaya. Penyimpanan objek S3, yang diakses melalui NVMe atau HDD, menyediakan backend yang dapat diskalakan untuk mengelola dataset besar, checkpoint, dan model inferensi.
- NVMe berkecepatan tinggi untuk dataset pelatihan dan akses latensi rendah
- HDD hemat biaya untuk penyimpanan jangka panjang dan arsip
Mengapa S3 Ideal untuk Beban Kerja AI
Penyimpanan yang kompatibel dengan S3 banyak diadopsi dalam pipeline AI karena API RESTful-nya, skalabilitas, dan integrasinya dengan kerangka kerja ML. Ini mendukung:
- Penyimpanan dataset dan model
- Checkpointing dan versi artefak
- Menyajikan model ke titik akhir inferensi
- Integrasi dengan TensorFlow, Pytorch, MLFLOW
Mengapa Ceph RGW Sangat Cocok untuk Penyimpanan AI S3
Ceph RGW adalah layanan penyimpanan objek sumber terbuka yang kompatibel dengan S3 yang menawarkan ketersediaan tinggi, konsistensi yang kuat, dan skalabilitas skala petabyte. Fitur utama termasuk:
- Mendukung skalabilitas di ratusan node
- Menawarkan konsistensi yang kuat dan pengkodean penghapusan untuk daya tahan
- Menyediakan replikasi multi-situs terintegrasi untuk kasus penggunaan cloud hibrida
- Dapat diterapkan pada perangkat keras komoditas yang hemat biaya
Ini menjadikan Ceph RGW backend yang kuat untuk penyimpanan objek yang berfokus pada AI baik pada skala petabyte maupun lingkungan yang kritis terhadap kinerja.
Kebutuhan untuk Penyeimbangan Beban yang Tinggi Ketersediaan di Ceph RGW
Ceph RGW tidak memiliki status, memungkinkan skalabilitas horizontal. Namun, untuk memberikan:
- Ketersediaan tinggi
- Dukungan failover
- Skalabilitas kinerja
Anda memerlukan penyeimbang beban front-end yang dapat secara andal dan efisien mendistribusikan permintaan S3 yang masuk (GET, PUT, DELETE) di beberapa instance RGW.
Tanpa penyeimbangan beban yang tepat, satu node RGW atau server front-end dapat menjadi titik kemacetan atau titik kegagalan tunggal.
Opsi Penyeimbang Beban Sumber Terbuka untuk Ceph RGW
Dua arsitektur utama yang umum digunakan dengan penyeimbang beban sumber terbuka:
-
Berdasarkan Ingress (HAProxy + Keepalived + Multi-VIP + DNS RR)
- Dukungan Layer 7 (HTTP)
- Mendukung terminasi TLS, routing multi-tenant berbasis SNI
- Cocok untuk cloud publik atau penyebaran multi-tenant
- Latensi sedikit lebih tinggi dan memerlukan penyesuaian yang hati-hati untuk menghindari kemacetan
- Pada skala penyebaran yang lebih besar, beberapa server perangkat keras berkinerja tinggi diperlukan untuk mencegah HAProxy menjadi bottleneck.
-
LVS Tun Conntrackd Connections Tertimbang Tertimbang (WLC)
- Tunneling IP-in-IP Layer 4
- Throughput tinggi dan penggunaan CPU rendah
- Menghindari penyeimbang untuk lalu lintas kembali
- Terbaik untuk jaringan internal privat berkecepatan tinggi
Mengapa LVS TUN Lebih Baik untuk Penyimpanan AI S3 Pribadi Berbasis NVMe
Untuk kluster pelatihan AI berbasis NVMe internal, kinerja adalah prioritas utama:
- LVS TUN mencapai bandwidth mendekati laju garis
- Tidak mengakhiri TLS, mengurangi beban CPU
- conntrackd memastikan failover yang mulus tanpa gangguan klien
- Tidak ada inspeksi lapisan aplikasi yang mengurangi latensi
Dengan demikian, LVS TUN lebih cocok daripada HAProxy untuk penyimpanan objek AI internal berkecepatan tinggi (misalnya, jalur pelatihan kluster GPU).
Membandingkan LVS Tun vs Ingress untuk pribadi & amp; Aplikasi AI Cloud Publik
| Fitur | Ingress (Haproxy) | LVS Tun Conntrackd |
|---|---|---|
| Terminasi TLS | ✅ Ya | ❌ Tidak |
| Routing multi-penyewa | ✅ Ya | ❌ Tidak |
| Throughput | ❌ Terbatas | ✅ Laju garis |
| Latensi | ❌ Lebih tinggi | ✅ Lebih rendah |
| Pemeriksaan kesehatan | ✅ http | ❌ TCP/ICMP |
| Integrasi DNS | ✅ Diperlukan | ❌ Tidak diperlukan |
| Kasus penggunaan ideal | Cloud publik | AI/HPC pribadi |
Bagaimana UniVirStor Ambedded Mendukung LVS Load Balancer untuk Ceph RGW
UniVirStor menawarkan dukungan asli untuk mode LVS TUN, termasuk:
- Pengaturan otomatis berbasis Ansible
- Ketersediaan tinggi dengan keepalived dan conntrackd
- Hook pemeriksaan kesehatan dan metrik kinerja
- Routing yang dioptimalkan untuk gateway S3 throughput tinggi
Ini menjadikan UniVirStor ideal untuk pelanggan yang membangun danau data AI atau kluster AI berbasis GPU yang membutuhkan kinerja dan keandalan dari Ceph RGW.
Kesimpulan
Memilih arsitektur load balancer yang tepat sangat penting untuk membangun backend penyimpanan S3 yang kuat dan skalabel untuk AI.
- Untuk kluster AI pribadi, gunakan LVS TUN + conntrackd untuk memaksimalkan kinerja.
- Untuk layanan yang menghadapi publik atau S3 multi-tenant, gunakan HAProxy berbasis Ingress untuk fleksibilitas dan penanganan TLS yang lebih baik.
UniVirStor dari Ambedded membantu Anda menerapkan kedua skenario secara efisien dengan penyetelan tingkat produksi dan dukungan ketersediaan tinggi.