S3-Speicher-Lastenausgleich für KI mit Ceph RGW
KI-Workloads erfordern skalierbaren, hochgradigen S3-Speicher für Trainingsdaten, Modelle und Inferenzausgaben. Ceph RGW bietet ein zuverlässiges, S3-kompatibles Backend, aber die Leistung hängt stark von der Lastverteilung ab. Für private KI-Cluster, die NVMe verwenden, bietet LVS TUN nahezu lineare Bandbreite und niedrige Latenz. Ambedded’s UniVirStor unterstützt nativ LVS TUN mit automatischer Einrichtung und HA-Design, was es ideal für leistungskritische AI-Speicherumgebungen macht.
Die folgenden Schlüsselpunkte fassen die Notwendigkeit und die Begründung für jede Designentscheidung zusammen.
- Warum KI skalierbaren und effizienten Speicher benötigt
- Warum S3 ideal für KI-Workloads ist
- Warum Ceph RGW gut für KI-S3-Speicher geeignet ist
- Der Bedarf an hochverfügbarem Lastenausgleich in Ceph RGW
- Open-Source-Lastenausgleichsoptionen für Ceph RGW
- Warum LVS TUN besser für NVMe-basierten privaten AI S3-Speicher ist
- Vergleich des LVS -Tun mit Eingang für Private & amp; Öffentliche Cloud -AI -Anwendungen
- Wie Ambedded's UniVirStor LVS-Lastenausgleich für Ceph RGW unterstützt
- Fazit
Warum KI skalierbaren und effizienten Speicher benötigt
Moderne AI-Workloads erfordern sowohl schnellen Zugriff auf Trainingsdaten als auch kosteneffizienten Langzeitspeicher. S3-Objektspeicher, der über NVMe oder HDD zugegriffen wird, bietet ein skalierbares Backend zur Verwaltung großer Datensätze, Checkpoints und Inferenzmodelle.
- Hochgeschwindigkeits-NVMe für Trainingsdatensätze und latenzfreien Zugriff
- Kosteneffiziente HDD für Langzeitspeicher und Archive
Warum S3 ideal für KI-Workloads ist
S3-kompatibler Speicher wird in AI-Pipelines aufgrund seiner RESTful-API, Skalierbarkeit und Integration mit ML-Frameworks weit verbreitet eingesetzt. Er unterstützt:
- Datensatz- und Modell-Speicherung
- Checkpointing und Artefakt-Versionierung
- Bereitstellung von Modellen für Inferenzendpunkte
- Integration mit Tensorflow, Pytorch, Mlflow
Warum Ceph RGW gut für KI-S3-Speicher geeignet ist
Ceph RGW ist ein Open-Source-Objektspeicherdienst, der S3-kompatibel ist und hohe Verfügbarkeit, starke Konsistenz und Petabyte-Skalierbarkeit bietet. Zu den Hauptmerkmalen gehören:
- Unterstützt Skalierbarkeit über Hunderte von Knoten
- Bietet starke Konsistenz und Löschcodierung für Haltbarkeit
- Bietet integrierte Multi-Standort-Replikation für hybride Cloud-Anwendungsfälle
- Kann auf kostengünstiger Standardhardware bereitgestellt werden
Dies macht Ceph RGW zu einem leistungsstarken Backend für AI-fokussierten Objektspeicher sowohl im Petabyte-Maßstab als auch in leistungs-kritischen Umgebungen.
Der Bedarf an hochverfügbarem Lastenausgleich in Ceph RGW
Ceph RGW ist zustandslos und ermöglicht horizontale Skalierung. Um jedoch zu liefern:
- Hohe Verfügbarkeit
- Failover-Unterstützung
- Leistungs-Skalierbarkeit
Sie benötigen einen Front-End-Lastenausgleich, der eingehende S3-Anfragen (GET, PUT, DELETE) zuverlässig und effizient auf mehrere RGW-Instanzen verteilen kann.
Ohne ordnungsgemäßen Lastenausgleich kann ein einzelner RGW-Knoten oder Front-End-Server zum Engpass oder zum einzigen Ausfallpunkt werden.
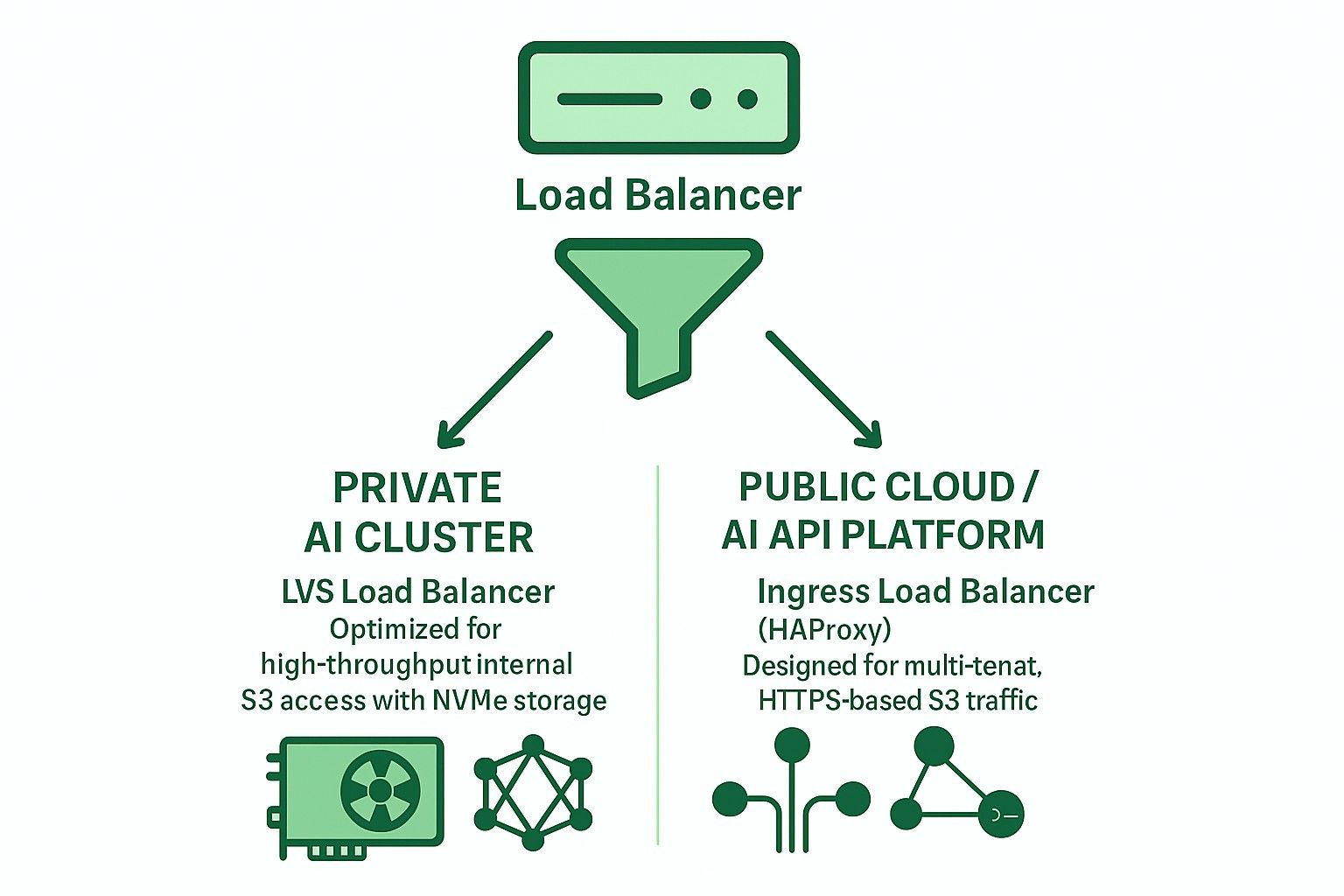
Open-Source-Lastenausgleichsoptionen für Ceph RGW
Zwei primäre Architekturen werden häufig mit Open-Source-Lastenausgleichern verwendet:
-
Ingress-basiert (HAProxy + Keepalived + Multi-VIP + DNS RR)
- Layer 7 (HTTP) Unterstützung
- Unterstützt TLS-Terminierung, SNI-basiertes Multi-Tenant-Routing
- Geeignet für öffentliche Cloud- oder Multi-Tenant-Bereitstellungen
- Leicht höhere Latenz und erfordert sorgfältige Anpassungen, um Engpässe zu vermeiden
- Bei größeren Bereitstellungsskalen sind mehrere leistungsstarke Hardware-Server erforderlich, um zu verhindern, dass HAProxy zum Flaschenhals wird.
-
LVS Tun Conntrackd gewichtete kleinste Verbindungen (WLC)
- Layer 4 IP-in-IP-Tunneling
- Hoher Durchsatz und niedrige CPU-Auslastung
- Umgeht den Lastenausgleich für Rückverkehr
- Am besten für private, hochgeschwindigkeitsinterne Netzwerke
Warum LVS TUN besser für NVMe-basierten privaten AI S3-Speicher ist
Für interne, NVMe-basierte KI-Trainingscluster hat die Leistung oberste Priorität:
- LVS TUN erreicht nahezu liniennahe Bandbreite
- Beendet TLS nicht, wodurch die CPU-Überlastung verringert wird
- conntrackd sorgt für nahtlosen Failover ohne Unterbrechung des Clients
- Keine Anwendungsschichtinspektion reduziert die Latenz.
Daher ist LVS TUN besser geeignet als HAProxy für Hochgeschwindigkeits-Internes AI-Objektspeicher (z.B. GPU-Cluster-Trainingspipelines).
Vergleich des LVS -Tun mit Eingang für Private & amp; Öffentliche Cloud -AI -Anwendungen
| Funktion | Ein- (Haproxy) | LVS Tun Conntrackd |
|---|---|---|
| TLS-Beendigung | ✅ Ja | ❌ Nein |
| Multi-Tenant-Routing | ✅ Ja | ❌ Nein |
| Durchsatz | ❌ Eingeschränkt | ✅ Zeilenrate |
| Latenz | ❌ Höher | ✅ Niedriger |
| Gesundheitsprüfungen | ✅ http | ❌ TCP/ICMP |
| DNS-Integration | ✅ Erforderlich | ❌ Nicht benötigt |
| Idealer Anwendungsfall | Öffentliche Cloud | Private KI/HPC |
Wie Ambedded's UniVirStor LVS-Lastenausgleich für Ceph RGW unterstützt
UniVirStor bietet native Unterstützung für den LVS TUN-Modus, einschließlich:
- Automatisierte Einrichtung auf Ansible-Basis
- Hohe Verfügbarkeit mit keepalived und conntrackd
- Health-Check-Hooks und Leistungskennzahlen
- Optimiertes Routing für Hochdurchsatz-S3-Gateways
Das macht UniVirStor ideal für Kunden, die KI-Datenseen oder GPU-basierte KI-Cluster aufbauen, die sowohl Leistung als auch Zuverlässigkeit von Ceph RGW verlangen.
Fazit
Die Wahl der richtigen Lastenausgleichsarchitektur ist entscheidend für den Aufbau eines robusten, skalierbaren S3-Speicher-Backends für KI.
- Für private KI-Cluster verwenden Sie LVS TUN + conntrackd, um die Leistung zu maximieren.
- Für öffentlich zugängliche Dienste oder Multi-Tenant-S3 verwenden Sie Ingress-basiertes HAProxy für bessere Flexibilität und TLS-Verwaltung.
Ambedded's UniVirStor hilft Ihnen, beide Szenarien effizient mit produktionsgerechter Feinabstimmung und Unterstützung für hohe Verfügbarkeit bereitzustellen.