S3 Opslag Load Balancing voor AI met Ceph RGW
AI-werkbelastingen vereisen schaalbare, hoge doorvoersnelheid S3-opslag voor trainingsgegevens, modellen en inferentie-uitvoer. Ceph RGW biedt een betrouwbare, S3-compatibele backend, maar de prestaties zijn sterk afhankelijk van load balancing. Voor privé AI-clusters die NVMe gebruiken, biedt LVS TUN bijna lijn-snelheid bandbreedte en lage latentie. De UniVirStor van Ambedded ondersteunt van nature LVS TUN met geautomatiseerde installatie en HA-ontwerp, waardoor het ideaal is voor prestatiekritische AI-opslagomgevingen.
De volgende kernpunten samenvatten de noodzaak en rechtvaardiging voor elke ontwerpe keuze.
- Waarom AI schaalbare en efficiënte opslag nodig heeft
- Waarom S3 ideaal is voor AI-werkbelastingen
- Waarom Ceph RGW een sterke keuze is voor AI S3-opslag
- De behoefte aan hoge beschikbaarheid en load balancing in Ceph RGW
- Open-source load balancer opties voor Ceph RGW
- Waarom LVS TUN beter is voor NVMe-gebaseerde privé AI S3-opslag
- Vergelijking van LVS TUN versus Ingress voor privé & amp; Public Cloud AI -applicaties
- Hoe Ambedded's UniVirStor LVS Load Balancer ondersteunt voor Ceph RGW
- Conclusie
Waarom AI schaalbare en efficiënte opslag nodig heeft
Moderne AI-werkbelastingen vereisen zowel snelle toegang tot trainingsgegevens als kosteneffectieve opslag op lange termijn. S3-objectopslag, toegankelijk via NVMe of HDD, biedt een schaalbare backend voor het beheren van grote datasets, checkpoints en inferentiemodellen.
- Hoge snelheid NVMe voor trainingsdatasets en lage latentie toegang
- Kosteneffectieve HDD voor opslag op lange termijn en archieven
Waarom S3 ideaal is voor AI-werkbelastingen
S3-compatibele opslag wordt veel gebruikt in AI-pijplijnen vanwege de RESTful API, schaalbaarheid en integratie met ML-frameworks. Het ondersteunt:
- Dataset- en modelopslag
- Checkpointing en artifactversiebeheer
- Modellen aanbieden aan inferentie-eindpunten
- Integratie met TensorFlow, Pytorch, Mlflow
Waarom Ceph RGW een sterke keuze is voor AI S3-opslag
Ceph RGW is een open-source, S3-compatibele objectopslagdienst die hoge beschikbaarheid, sterke consistentie en petabyte-schaal schaalbaarheid biedt. Belangrijke kenmerken zijn:
- Ondersteunt schaalbaarheid over honderden nodes
- Biedt sterke consistentie en foutencodering voor duurzaamheid
- Biedt geïntegreerde multi-site replicatie voor hybride cloudgebruiksscenario's
- Kan worden geïmplementeerd op kosteneffectieve commodity-hardware
Dit maakt Ceph RGW een krachtige backend voor AI-gerichte objectopslag, zowel op petabyte-schaal als in prestatiekritische omgevingen.
De behoefte aan hoge beschikbaarheid en load balancing in Ceph RGW
Ceph RGW is staatloos, waardoor horizontale schaling mogelijk is. Echter om te leveren:
- Hoge beschikbaarheid
- Failover-ondersteuning
- Prestatie-schaalbaarheid
Je hebt een front-end load balancer nodig die inkomende S3-verzoeken (GET, PUT, DELETE) betrouwbaar en efficiënt kan verdelen over meerdere RGW-instanties.
Zonder goede load balancing kan een enkele RGW-knoop of front-end server een bottleneck of enkelvoudig punt van falen worden.
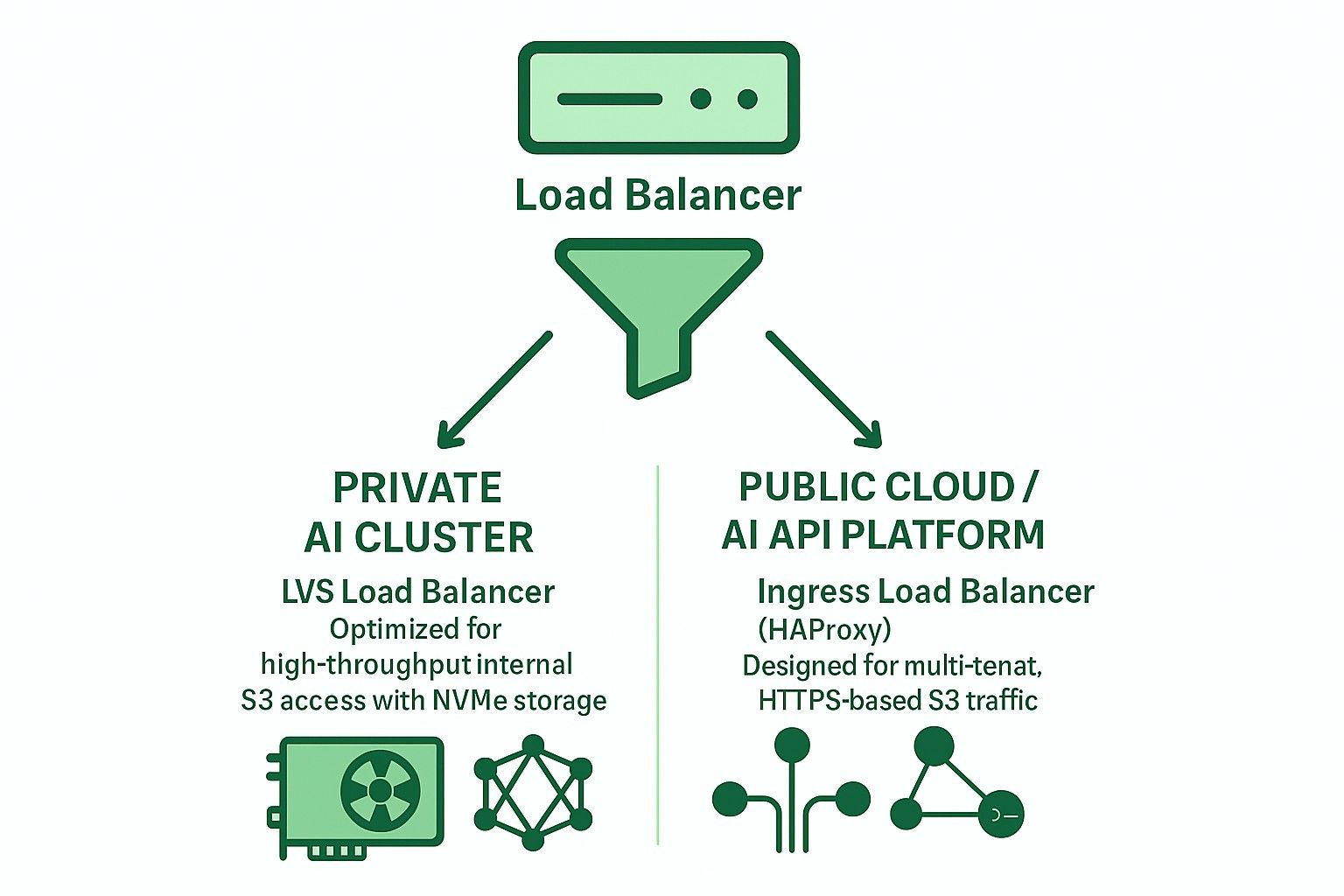
Open-source load balancer opties voor Ceph RGW
Twee primaire architecturen worden vaak gebruikt met open-source load balancers:
-
Ingress-gebaseerd (HAProxy + Keepalived + Multi-VIP + DNS RR)
- Laag 7 (HTTP) ondersteuning
- Ondersteunt TLS-terminatie, SNI-gebaseerde multi-tenant routering
- Geschikt voor publieke cloud of multi-tenant implementaties
- Iets hogere latentie en vereist zorgvuldige afstemming om bottlenecks te vermijden
- Bij grotere implementatieschalen zijn meerdere high-performance hardware servers nodig om te voorkomen dat HAProxy een bottleneck wordt.
-
LVS tun conntrackd gewogen de minste verbindingen (WLC)
- Laag 4 ip-in-ip tunneling
- Hoge doorvoer en laag CPU-gebruik
- Omzeilt de balancer voor retourverkeer
- Het beste voor privé, hoge-snelheid interne netwerken
Waarom LVS TUN beter is voor NVMe-gebaseerde privé AI S3-opslag
Voor interne, NVMe-gebaseerde AI-trainingsclusters is prestaties de hoogste prioriteit:
- LVS TUN bereikt bijna lijn-snelheid bandbreedte
- Beëindigt geen TLS, waardoor de CPU-overhead wordt verminderd
- conntrackd zorgt voor naadloze failover zonder onderbreking voor de klant
- Geen inspectie op applicatielaag vermindert latentie
Daarom is LVS TUN beter geschikt dan HAProxy voor hoge-snelheid interne AI-objectopslag (bijv. GPU-cluster trainingspijplijnen).
Vergelijking van LVS TUN versus Ingress voor privé & amp; Public Cloud AI -applicaties
| Kenmerk | Ingress (haproxy) | LVS TUN + conntrackd |
|---|---|---|
| TLS-terminatie | ✅ Ja | ❌ Nee |
| Multi-tenant routering | ✅ Ja | ❌ Nee |
| Doorvoer | ❌ Beperkt | ✅ Lijn-snelheid |
| Latentie | ❌ Hoger | ✅ Lager |
| Gezondheidscontroles | ✅ http | ❌ TCP/ICMP |
| DNS-integratie | ✅ Vereist | ❌ Niet nodig |
| Ideale gebruiksgeval | Publieke cloud | Privé AI/HPC |
Hoe Ambedded's UniVirStor LVS Load Balancer ondersteunt voor Ceph RGW
UniVirStor biedt native ondersteuning voor LVS TUN-modus, inclusief:
- Ansible-gebaseerde geautomatiseerde setup
- Hoge beschikbaarheid met keepalived en conntrackd
- Health check hooks en prestatiemetingen
- Geoptimaliseerde routering voor hoge doorvoersnelheid S3-gateways
Dit maakt UniVirStor ideaal voor klanten die AI-datalakes of GPU-gebaseerde AI-clusters bouwen die zowel prestaties als betrouwbaarheid van Ceph RGW vereisen.
Conclusie
Het kiezen van de juiste load balancer-architectuur is essentieel voor het bouwen van een robuuste, schaalbare S3-opslagbackend voor AI.
- Voor privé AI-clusters, gebruik LVS TUN + conntrackd om de prestaties te maximaliseren.
- Voor openbare diensten of multi-tenant S3, gebruik Ingress-gebaseerde HAProxy voor betere flexibiliteit en TLS-beheer.
Ambedded's UniVirStor helpt je beide scenario's efficiënt te implementeren met productieklare afstemming en ondersteuning voor hoge beschikbaarheid.