
High Data Availability and Durability
Ceph object storage achieves data availability through replication and advanced erasure coding whereby data is combined with parity information and then sharded and distributed across the storage pool.
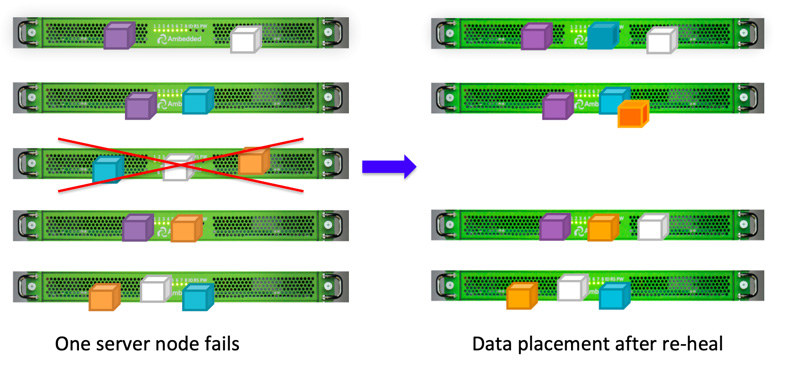
When a storage device fails, only a subset of the shards are needed to reheal the data, there is no rebuild time or degraded performance, and failed storage devices can be replaced when convenient.
Ceph combines widely distributed data and data scrubbing technology that continuously validates the data written on the media can enable you to achieve 15 nines of data durability.
Data Replication, Erasure Coding & Scrubbing
Object Replication
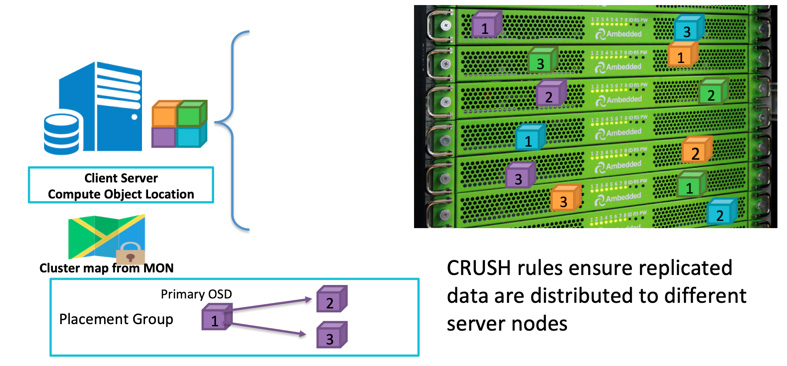
When a client is going to write data, it uses object ID and pool name to calculate which OSD it shall write to. After the client writes data to the OSD, the OSD copies the data to one or more OSDs. You can configure as many replications as you want to make the data be able to survive in case multiple OSDs fail concurrently. The Replication is similar to the RAID-1 of disk array but allows more copies of data. Because at scale, a simple RAID-1 replication may not sufficiently cover the risk of hardware failure anymore. The only downside of storing more replicas is the storage cost.
Ceph clients write data randomly to OSDs based on the CRUSH algorithm. If OSD disk or node fails, Ceph can re-heal the data from other replications stored in healthy OSDs.
You can define the failure domain to make Ceph store replicated data in different servers, racks, rooms, or data centers for avoiding data loss due to one or more failures of the whole failure domain. For example, if you have 15 storage servers installed in 5 racks ( 3 servers in each rack), you can use replica three and rack as the failure domain. Data write to the ceph cluster will always have three copies stored in three of the five racks. Data can survive with up to any 2 of the racks fail without degrading the client service. The CRUSH rule is the key to make Ceph Storage has no single point of failure.
Erasure Coding
Replication offers the best overall performance, but it is not much storage space-efficient. Especially if you need a higher degree of redundancy.
To have high data availability is why we used RAID-5 or RAID-6 in the past as an alternative to RAID-1. Parity RAID assures redundancy with much less storage overhead at the cost of storage performance (mostly write performance). Ceph uses erasure encoding to achieve a similar result. When the scale of your storage system becomes large, you may feel unconfident with allowing just one or two disks or failure domains to fail at the same time. The erasure code algorithm enables you to configure a higher level of redundancy but with less space of overhead.
Erasure coding chunks the original data into K data chunks and calculated extra M coding chunks. Ceph can recover the data maximum M failure domains fail in the meantime. Total K+M of chunks are store in the OSDs, which are in different failure domains.

Scrubbing
As part of maintaining data consistency and cleanliness, Ceph OSD Daemons can scrub objects within placement groups. That is, Ceph OSD Daemons can compare object metadata in one placement group with its replicas in placement groups stored on other OSDs. Scrubbing (usually performed daily) catches bugs or filesystem errors. Ceph OSD Daemons also perform deeper scrubbing by comparing data in objects bit-for-bit. Deep scrubbing (usually performed weekly) finds bad sectors on a drive that weren’t apparent in a light scrub.
Data Healing
Due to the data placement design of Ceph, data is healed by all healthy OSDs. There is no spare disk required for data re-heal. This can make the time to re-heal become much shorter compared to the disk array, which has to rebuild the lost data to the spare disk.
- Config CRUSH map and rules