
Hohe Datenverfügbarkeit und -haltbarkeit
Ceph-Objektspeicher erreicht Datenverfügbarkeit durch Replikation und fortschrittliche Löschcodierung, wobei Daten mit Paritätsinformationen kombiniert und dann in Fragmente aufgeteilt und über den Speicherpool verteilt werden.
Wenn ein Speichermedium ausfällt, sind nur eine Teilmenge der Fragmente erforderlich, um die Daten wiederherzustellen, es gibt keine Wiederaufbauzeit oder verschlechterte Leistung, und ausgefallene Speichermedien können nach Belieben ersetzt werden.
Ceph kombiniert weit verteilte Daten und Datenbereinigungs-Technologie, die kontinuierlich die auf dem Medium geschriebenen Daten validiert und es Ihnen ermöglicht, 15 Neunen an Datensicherheit zu erreichen.
Datenreplikation, Löschcodierung & Bereinigung
Objekt-Replikation
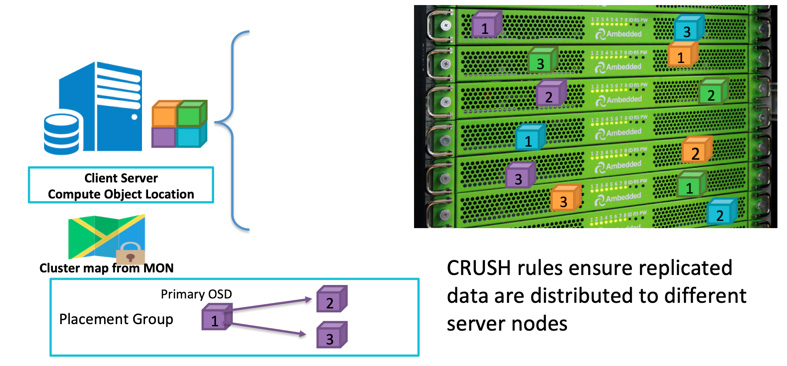
Wenn ein Client Daten schreiben möchte, verwendet er die Objekt-ID und den Pool-Namen, um zu berechnen, auf welchem OSD er schreiben soll. Nachdem der Client Daten auf den OSD geschrieben hat, kopiert der OSD die Daten auf einen oder mehrere OSDs. Sie können so viele Replikationen konfigurieren, wie Sie möchten, um sicherzustellen, dass die Daten überleben können, falls mehrere OSDs gleichzeitig ausfallen. Die Replikation ist ähnlich wie RAID-1 in einer Festplattenanordnung, ermöglicht jedoch mehr Kopien von Daten. Weil bei großen Mengen eine einfache RAID-1-Replikation möglicherweise nicht mehr ausreicht, um das Risiko eines Hardwareausfalls ausreichend abzudecken. Der einzige Nachteil beim Speichern von mehr Replikaten ist der Speicherplatzbedarf.
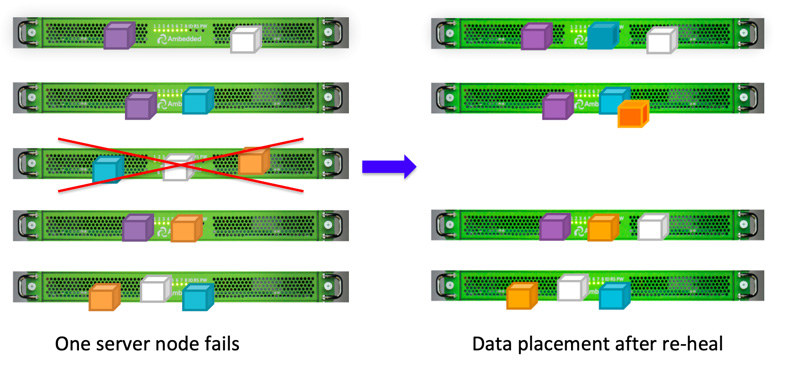
Ceph-Clients schreiben Daten zufällig auf OSDs basierend auf dem CRUSH-Algorithmus.Wenn die OSD-Festplatte oder der Knoten ausfällt, kann Ceph die Daten aus anderen Replikationen in gesunden OSDs wieder heilen.
Sie können den Ausfallbereich definieren, um Ceph dazu zu bringen, replizierte Daten auf verschiedenen Servern, Regalen, Räumen oder Rechenzentren zu speichern, um Datenverlust aufgrund eines oder mehrerer Ausfälle des gesamten Ausfallbereichs zu vermeiden.Zum Beispiel, wenn Sie 15 Speicherserver in 5 Racks installiert haben (3 Server in jedem Rack), können Sie Replica Three und Rack als Fehlerdomäne verwenden.Daten, die in den Ceph-Cluster geschrieben werden, werden immer in drei der fünf Racks in drei Kopien gespeichert.Die Daten können überleben, selbst wenn bis zu 2 der Racks ausfallen, ohne den Kundenservice zu beeinträchtigen.Die CRUSH-Regel ist der Schlüssel, um sicherzustellen, dass Ceph-Speicher keinen Single Point of Failure aufweist.
Fehlerkorrekturverfahren
Replikation bietet die beste Gesamtleistung, ist aber nicht besonders speicherplatzeffizient.Insbesondere wenn Sie einen höheren Grad an Redundanz benötigen.
Um eine hohe Datenverfügbarkeit zu haben, ist der Grund, warum wir in der Vergangenheit RAID-5 oder RAID-6 als Alternative zu RAID-1 verwendet haben.Parity RAID gewährleistet Redundanz mit deutlich geringerem Speicheroverhead zu Lasten der Speicherleistung (hauptsächlich Schreibleistung).Ceph verwendet Fehlerkorrekturcodierung, um ein ähnliches Ergebnis zu erzielen.Wenn das Ausmaß Ihres Speichersystems groß wird, fühlen Sie sich möglicherweise unsicher, wenn Sie zulassen, dass nur eine oder zwei Festplatten oder Fehlerdomänen gleichzeitig ausfallen.Der Löschcode-Algorithmus ermöglicht es Ihnen, einen höheren Redundanzgrad bei geringerem Platzbedarf zu konfigurieren.
Das Löschkodieren teilt die Originaldaten in K Datenchunks und berechnete zusätzliche M Codierungschunks auf.Ceph kann die Daten maximal M Ausfallbereiche wiederherstellen, während sie ausfallen.In den OSDs werden insgesamt K+M Chunks gespeichert, die sich in verschiedenen Ausfallbereichen befinden.

Reinigung
Im Rahmen der Aufrechterhaltung der Datenkonsistenz und -sauberkeit können Ceph OSD-Daemons Objekte innerhalb von Platzierungsgruppen überprüfen. Das heißt, Ceph OSD-Daemons können Metadaten von Objekten in einer Platzierungsgruppe mit den Replikaten in Platzierungsgruppen vergleichen, die auf anderen OSDs gespeichert sind. Das Reinigen (normalerweise täglich durchgeführt) erfasst Fehler oder Dateisystemfehler. Ceph OSD-Daemons führen auch eine tiefere Überprüfung durch, indem sie die Daten in den Objekten bitweise vergleichen. Die gründliche Reinigung (normalerweise wöchentlich durchgeführt) findet fehlerhafte Sektoren auf einer Festplatte, die bei einer oberflächlichen Reinigung nicht erkennbar waren.
Datenheilung
Aufgrund des Datenplatzierungsdesigns von Ceph wird Daten von allen gesunden OSDs wiederhergestellt. Es ist kein Ersatzlaufwerk für die Datenwiederherstellung erforderlich. Dadurch kann die Zeit für die Wiederherstellung wesentlich kürzer sein im Vergleich zu einem Festplattenarray, bei dem die verlorenen Daten auf das Ersatzlaufwerk neu aufgebaut werden müssen.
- CRUSH-Karte und Regeln konfigurieren