
Ketersediaan dan Ketahanan Data Tinggi
Penyimpanan objek Ceph mencapai ketersediaan data melalui replikasi dan pengkodean penghapusan canggih di mana data digabungkan dengan informasi paritas dan kemudian dibagi dan didistribusikan di seluruh kolam penyimpanan.
Ketika perangkat penyimpanan gagal, hanya sebagian dari shard yang diperlukan untuk memulihkan data, tidak ada waktu pembangunan kembali atau penurunan kinerja, dan perangkat penyimpanan yang gagal dapat diganti saat nyaman.
Ceph menggabungkan data yang tersebar luas dan teknologi pembersihan data yang terus-menerus memvalidasi data yang ditulis di media dapat memungkinkan Anda mencapai 15 sembilan ketahanan data.
Replikasi Data, Pengkodean Penghapusan & Pembersihan
Replikasi Objek
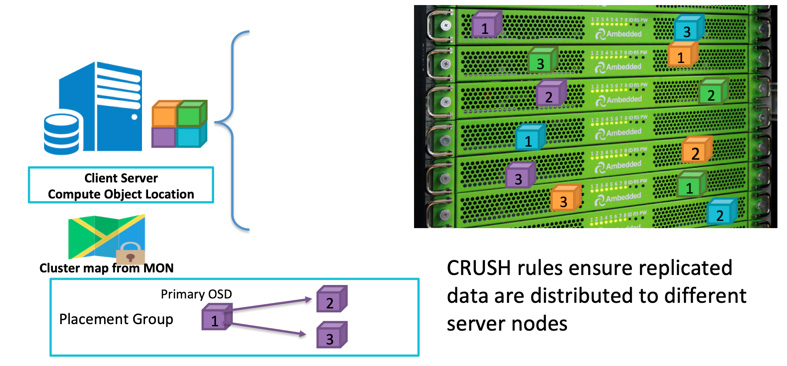
Ketika seorang klien akan menulis data, ia menggunakan ID objek dan nama pool untuk menghitung ke OSD mana ia akan menulis. Setelah klien menulis data ke OSD, OSD akan menyalin data ke satu atau lebih OSD. Anda dapat mengkonfigurasi sebanyak mungkin replikasi yang Anda inginkan agar data dapat bertahan jika beberapa OSD gagal secara bersamaan. Replikasi mirip dengan RAID-1 dari larik disk tetapi memungkinkan lebih banyak salinan data. Karena dalam skala besar, replikasi RAID-1 sederhana mungkin tidak lagi cukup untuk menutupi risiko kegagalan perangkat keras. Satu-satunya kelemahan dari menyimpan lebih banyak replika adalah biaya penyimpanan.
Klien Ceph menulis data secara acak ke OSD berdasarkan algoritma CRUSH.Jika disk OSD atau node gagal, Ceph dapat menyembuhkan kembali data dari replikasi lain yang disimpan di OSD yang sehat.
Anda dapat menentukan domain kegagalan untuk membuat Ceph menyimpan data yang direplikasi di server, rak, ruangan, atau pusat data yang berbeda untuk menghindari kehilangan data akibat satu atau lebih kegagalan dari seluruh domain kegagalan.Sebagai contoh, jika Anda memiliki 15 server penyimpanan yang terpasang di 5 rak (3 server di setiap rak), Anda dapat menggunakan replika tiga dan rak sebagai domain kegagalan.Data yang ditulis ke klaster Ceph akan selalu memiliki tiga salinan yang disimpan di tiga dari lima rak.Data dapat bertahan dengan hingga 2 rak gagal tanpa mengurangi layanan klien.Aturan CRUSH adalah kunci untuk membuat Penyimpanan Ceph memiliki tidak ada titik kegagalan tunggal.
Penghapusan Kode
Replikasi menawarkan kinerja terbaik secara keseluruhan, tetapi tidak efisien dalam penggunaan ruang penyimpanan.Terutama jika Anda membutuhkan tingkat ridundansi yang lebih tinggi.
Untuk memiliki ketersediaan data yang tinggi, itulah mengapa kami menggunakan RAID-5 atau RAID-6 di masa lalu sebagai alternatif dari RAID-1.RAID Paritas menjamin keberlanjutan dengan overhead penyimpanan yang jauh lebih sedikit dengan biaya kinerja penyimpanan (terutama kinerja tulis).Ceph menggunakan enkoding erasure untuk mencapai hasil yang serupa.Ketika skala sistem penyimpanan Anda menjadi besar, Anda mungkin merasa tidak percaya diri jika hanya mengizinkan satu atau dua disk atau domain kegagalan gagal pada saat yang sama.Algoritma kode penghapusan memungkinkan Anda mengonfigurasi tingkat ridundansi yang lebih tinggi tetapi dengan overhead ruang yang lebih sedikit.
Kodifikasi penghapusan membagi data asli menjadi K data chunk dan menghitung tambahan M coding chunk.Ceph dapat memulihkan data maksimum M domain kegagalan jika terjadi kegagalan dalam waktu yang bersamaan.Total K+M dari chunk disimpan di OSD, yang berada di domain kegagalan yang berbeda.

Menggosok
Sebagai bagian dari menjaga konsistensi dan kebersihan data, Ceph OSD Daemons dapat membersihkan objek dalam grup penempatan. Yaitu, Ceph OSD Daemons dapat membandingkan metadata objek dalam satu grup penempatan dengan replikanya dalam grup penempatan yang disimpan di OSD lain. Scrubbing (biasanya dilakukan setiap hari) menangkap bug atau kesalahan sistem file. Ceph OSD Daemons juga melakukan pemeriksaan yang lebih mendalam dengan membandingkan data dalam objek bit demi bit. Pembersihan mendalam (biasanya dilakukan seminggu sekali) menemukan sektor-sektor buruk pada drive yang tidak terlihat dalam pembersihan ringan.
Pemulihan Data
Dikarenakan desain penempatan data Ceph, data diperbaiki oleh semua OSD yang sehat. Tidak ada disk cadangan yang diperlukan untuk memperbaiki data. Hal ini dapat membuat waktu pemulihan menjadi lebih singkat dibandingkan dengan array disk, yang harus membangun kembali data yang hilang ke disk cadangan.
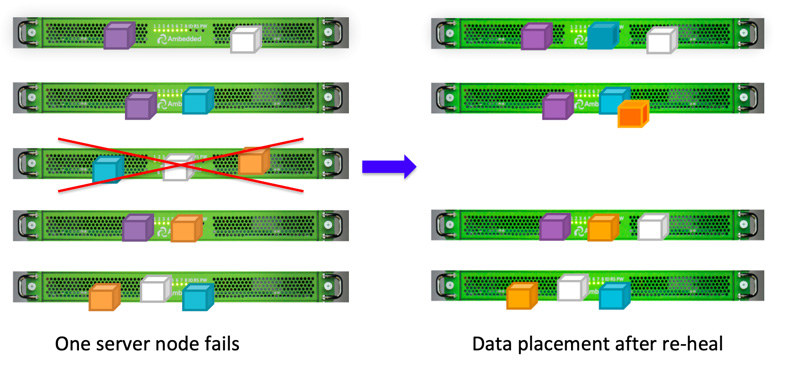
- Konfigurasi peta CRUSH dan aturan