
高資料可用性與持久性
Ceph 的物件儲存(object storage)透過資料複製 (replication) 和進階糾刪碼 (erasure coding) 來實現資料可用性。糾刪碼的運作方式是將資料與同位資訊 (parity information) 結合,然後將其分割成多個碎片,並分散儲存在整個儲存池中。
當儲存裝置發生故障時,只需部分區塊即可復原資料,無需重建時間,也不會出現效能下降;而故障的儲存裝置可以在方便時再進行更換。
Ceph 結合廣泛分散的資料與持續驗證寫入媒體資料的資料清洗(data scrubbing)技術,可讓你達到 15 個 9 的資料持久性。
資料複寫、糾刪碼與校驗
物件複寫
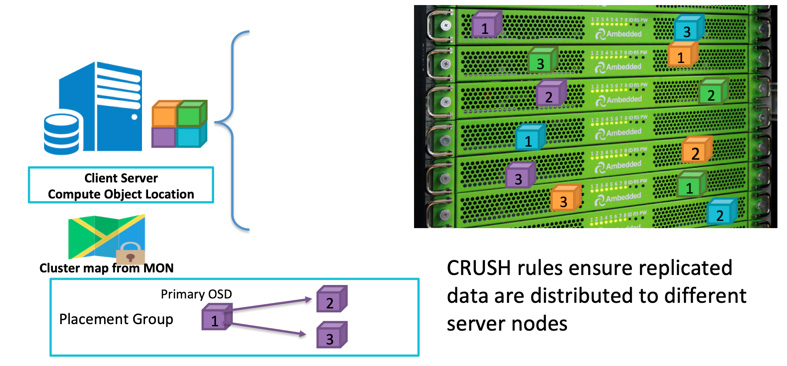
當客戶端要寫入資料時,它會使用物件 ID (object ID) 和儲存池名稱 (pool name) 來計算應該寫入哪一個 OSD。在客戶端將資料寫入該 OSD 後,該 OSD 會將資料複製到一個或多個其他的 OSD。你可依需求設定複本數,以確保資料在多個 OSD 同時故障的情況下依然能夠存活。複寫機制 (Replication) 類似於磁碟陣列的 RAID-1 ,但允許建立更多份的資料副本。隨著規模擴大,單純的 RAID-1 複製可能不再足以應對硬體故障的風險。而儲存更多副本的唯一缺點就是會增加儲存成本。
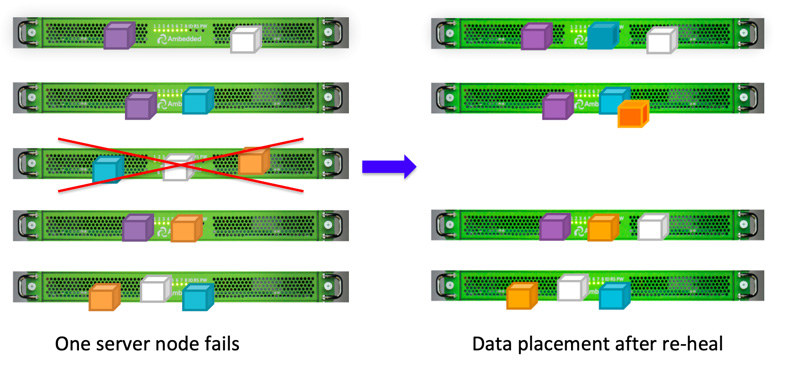
Ceph 客戶端會依據CRUSH 演算法,將資料隨機寫入各個 OSD。 如果 OSD 磁碟或節點故障, Ceph 可以從儲存在其他健康 OSD 上的副本中, 重新修復 (re-heal) 資料 。
您可以 定義故障域 (failure domain) ,讓Ceph 將複寫資料分散儲存在不同的伺服器、機櫃、機房或資料中心,以避免因整個故障域的一次或多次故障而造成資料遺失。舉例來說,如果您在 5 個機櫃中安裝了 15 台儲存伺服器(每個機櫃 3 台伺服器),您可以設定副本數為 3 ,並將機櫃 (rack) 定義為故障域。如此一來,寫入 Ceph 叢集的資料將始終有三份副本,分別儲存在這五個機櫃中的其中三個。即使其中任意兩個機櫃同時故障,資料仍可存活且不影響客戶端服務。 CRUSH rule 是讓 Ceph 儲存沒有單點故障的關鍵。
糾刪碼 (Erasure Coding)
資料複寫 (Replication) 提供最佳的整體效能,但儲存空間的使用效率不高,尤其在需要較高冗餘度時更是如此。
過去我們之所以使用 RAID-5 或 RAID-6 來取代 RAID-1 ,正是為了實現高資料可用性。同位元 RAID (Parity RAID) 能夠以更少的儲存空間開銷來確保備援,但代價是犧牲儲存效能
(主要是寫入效能)。Ceph
則使用糾刪碼 (erasure encoding) 來達到類似的效果。當您的儲存系統規模變得很大時,只允許一到兩顆磁碟或一到兩個故障域同時失效可能讓人難以放心。糾刪碼演算法能讓您配置更高層級的備援,但卻只需更少的空間開銷。
糾刪碼會將原始資料切分為 K 個資料區塊,並計算出額外的 M 個編碼區塊。當最多有 M 個故障域同時失效時, Ceph 仍能復原資料。總計 K+M 個區塊會儲存在分屬不同故障域的 OSD 上。

資料清洗 (Scrubbing)
為了維護資料的一致性與乾淨度, Ceph OSD 守護進程 (Daemons) 會對放置群組 (PG) 內的物件進行資料清洗 (scrubbing) 。也就是說, Ceph OSD 守護進程會將某個 PG 中的物件中繼資料 (metadata),與儲存在其他 OSD 上、其副本所在 PG 的中繼資料進行比對。一般清洗 (Scrubbing):通常每天執行一次,用於發現程式錯誤或檔案系統錯誤。深度清洗 (Deep Scrubbing):通常每週執行一次,透過逐位元 (bit-for-bit) 的方式比對物件中的資料,以找出在輕度清洗中未能顯現的磁碟壞軌。
資料修復 (Data Healing)
由於 Ceph 的資料放置設計,資料由所有健康的 OSD 共同修復,無需使用備援 (spare) 磁碟。相較於必須將遺失資料重建到備援磁碟的傳統磁碟陣列,這能大幅縮短修復時間。
- 設定 Ceph CRUSH Map 與 Rule