分散ストレージ
Cephを使用して、高可用性でデータを格納するためのサーバークラスターを構築することができます。データのレプリケーションまたはエラーコードのチャンクは、事前に定義された異なる障害ドメインに属するデバイスに分散的に格納されます。Cephは、複数のデバイス、サーバーノード、ラック、またはサイトが同時に故障してもデータを失わずにデータサービスを維持することができます。
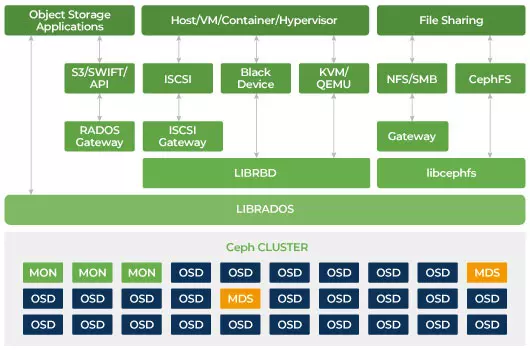
Cephソフトウェア定義ストレージ
クライアントは、Cephの分散ストレージアルゴリズムCRUSHを利用して、すべてのストレージデバイスと直接やり取りします。これにより、ストレージシステムのスケーラビリティを制限する従来のホストバスアダプタ(HBA)によるボトルネックがなくなります。Cephは、エクサバイトスケールまで容量とパフォーマンスを線形にスケーリングすることができます。
Cephはスケーラブルであり、単一障害点を持たないように設計されています。 モニター(MON)、オブジェクトストレージデーモン(OSD)、およびメタデータサーバー(MDS)は、Cephクラスター内の3つの主要なデーモン(Linuxプロセス)です。 通常、Cephクラスターには冗長性のために3つ以上のモニターノードがあります。 モニターはクラスターマップのマスターコピーを維持し、これによりCephクライアントはOSDとMDSと直接通信することができます。 これらのマップは、Cephデーモンがお互いと連携するために必要な重要なクラスタ状態です。 モニターは、デーモンとクライアント間の認証を管理する責任もあります。 奇数のモニターはクラスターマップをクオラムを使用して維持します。 このアルゴリズムは、モニター上の単一障害点を回避し、彼らの合意が有効であることを保証します。 CephのオブジェクトストレージデーモンであるOSDです。 データを保存し、データの複製、回復、再バランスを処理し、他のOSDデーモンのハートビートをチェックしてCephモニターにいくつかの監視情報を提供します。 すべてのストレージサーバーは、1つまたは複数のOSDデーモンを実行し、1つのストレージデバイスごとに1つ実行されます。 冗長性と高い可用性のためには通常、少なくとも3つのOSDが必要です。 MDSデーモンは、Cephファイルシステムに保存されているファイルに関連するメタデータを管理し、共有Cephストレージクラスタへのアクセスを調整します。 冗長性のために複数のアクティブなMDSを持つことができ、各MDSの負荷をバランスさせることができます。 共有ファイルシステムを使用する場合にのみ、1つ以上のメタデータサーバー(MDS)が必要です。
Cephはスケーラブルなストレージです
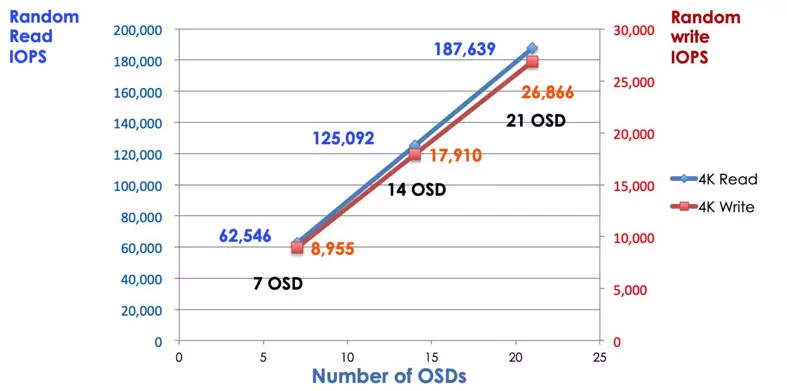
従来のストレージシステムでは、クライアントは中央集権的なコンポーネント(例:ホストバスアダプタまたはゲートウェイ)と通信し、これは複雑なサブシステムへの唯一の入り口です。 集中型コントローラーは、パフォーマンスと拡張性の両方に制限を課し、単一障害点を導入します。 集中コンポーネントがダウンすると、システム全体もダウンします。 Cephクライアントはモニタから最新のクラスタマップを取得し、CRUSHアルゴリズムを使用してクラスタ内のどのOSDを計算するかを決定します。 このアルゴリズムにより、クライアントは集中コントローラーを経由せずに直接Ceph OSDと対話することができます。 CRUSHアルゴリズムは、スケーラビリティの制限を引き起こす単一のパスを排除します。 Ceph OSDクラスタはクライアントに共有ストレージプールを提供します。 容量やパフォーマンスが必要な場合は、新しいOSDを追加してプールをスケールアウトすることができます。 Cephクラスタのパフォーマンスは、OSDの数に比例しています。 OSDの数を増やすと、読み取り/書き込みIOPSが増加することが以下の図で示されています。
従来のディスクアレイは、RAIDコントローラを使用してデータをディスク障害から保護します。 RAID技術が発明された当時、ハードディスクドライブの容量は約20MBでした。 今日のディスク容量は16TBというほど大きいです。 RAIDグループ内の故障したディスクの再構築には1週間かかる場合があります。 RAIDコントローラーが故障したドライブを再構築している間、同時に2番目のディスクが故障する可能性があります。 再構築に時間がかかる場合、データの損失の可能性が高くなります。
Cephは、クラスタ内の他のすべての健全なドライブによって失われたデータを回復します。Cephは、故障したドライブに格納されているデータのみを再構築または修復します。もし健全なディスクが複数ある場合、回復時間は短くなります。
- Ceph CRUSHマップとルールを設定する