Gedistribueerde opslag
U kunt Ceph gebruiken om een servercluster te bouwen voor het opslaan van gegevens met hoge beschikbaarheid. Gegevensreplicaties of erasure code-chunks worden distributief opgeslagen in apparaten die behoren tot verschillende vooraf gedefinieerde storingsdomeinen. Ceph kan zijn dataservice behouden zonder gegevensverlies wanneer meerdere apparaten, servernodes, racks of locaties tegelijkertijd uitvallen.
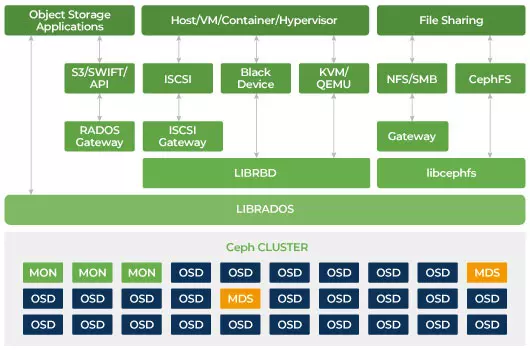
Ceph-software-gedefinieerde opslag
Klanten communiceren rechtstreeks met alle opslagapparaten om te lezen en schrijven met behulp van het gedistribueerde opslagalgoritme CRUSH van Ceph. Hierdoor wordt de bottleneck op de traditionele Host Bus Adapter (HBA) geëlimineerd, die de schaalbaarheid van het opslagsysteem beperkt. Ceph kan zijn capaciteit lineair schalen met prestaties tot op exabyteschaal.
Ceph is ontworpen om schaalbaar te zijn en geen enkel punt van falen te hebben. Monitor (MON), Object Storage Daemon (OSD), en Metadata Servers (MDS) zijn drie belangrijke daemons (Linux-processen) in de Ceph-cluster. Gewoonlijk heeft een Ceph-cluster drie of meer monitor-nodes voor redundantie. Monitoren onderhouden een masterkopie van de clusterkaarten, waardoor Ceph-clients rechtstreeks kunnen communiceren met OSD en MDS. Deze kaarten zijn cruciale clusterstatussen die nodig zijn voor Ceph-daemons om met elkaar te coördineren. Monitoren zijn ook verantwoordelijk voor het beheren van authenticatie tussen daemons en clients. Oneven aantallen monitoren behouden de clusterkaart met behulp van een quorum. Dit algoritme vermijdt het enkele faalpunt op de monitor en garandeert dat hun consensus geldig is. OSD is de objectopslagdemon voor Ceph. Het slaat gegevens op, handelt gegevensreplicatie, herstel, herverdeling af en geeft enige monitoringinformatie aan Ceph Monitors door andere OSD Daemons te controleren op hartslag. Elke opslagserver draait één of meerdere OSD-daemons, één per opslagapparaat. Voor redundantie en hoge beschikbaarheid zijn meestal minimaal 3 OSD's vereist. De MDS-daemon beheert metadata met betrekking tot bestanden die zijn opgeslagen op het Ceph-bestandssysteem en coördineert ook de toegang tot de gedeelde Ceph-opslagcluster. Je kunt meerdere actieve MDS hebben voor redundantie en de belasting van elke MDS in evenwicht brengen. Je hebt één of meer Metadata Servers (MDS) nodig alleen wanneer je het gedeelde bestandssysteem wilt gebruiken.
Ceph is schaalbare opslag
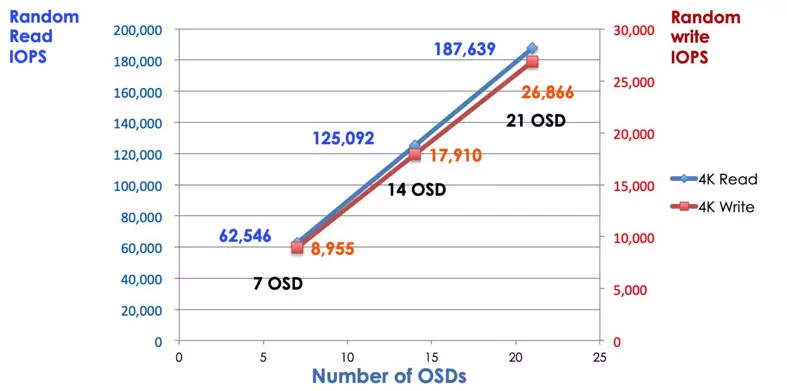
In een traditioneel opslagsysteem praten klanten met een gecentraliseerde component (bijv. host bus adapter of gateway), die een enkel toegangspunt is tot een complex subsysteem. De gecentraliseerde controller legt zowel beperkingen op aan prestaties en schaalbaarheid als introduceert een enkelvoudig storingspunt. Als het gecentraliseerde component uitvalt, valt het hele systeem ook uit. Ceph-clients halen de nieuwste clusterkaart op bij de monitors en gebruiken het CRUSH-algoritme om te berekenen welke OSD in de cluster. Dit algoritme stelt klanten in staat om rechtstreeks met Ceph OSD te communiceren zonder via een gecentraliseerde controller te gaan. Het CRUSH-algoritme elimineert het enkele pad, wat zorgt voor de beperking van schaalbaarheid. Ceph OSD-cluster biedt clients een gedeeld opslagpool. Wanneer u meer capaciteit of prestaties nodig heeft, kunt u nieuwe OSD toevoegen om de pool uit te breiden. De prestatie van een Ceph-cluster is recht evenredig met het aantal OSD. De volgende afbeelding toont de toename van de lees-/schrijf-IOPS als we het aantal OSD's verhogen.
Traditionele schijfarray gebruikt de RAID-controller om gegevens te beschermen tegen schijfstoringen. De capaciteit van een harde schijf was ongeveer 20MB toen de RAID-technologie werd uitgevonden. Vandaag is de schijfcapaciteit zo groot als 16TB. De tijd om een mislukte schijf in de RAID-groep te herbouwen kan een week duren. Terwijl de RAID-controller de mislukte schijf aan het herbouwen is, bestaat er een kans dat er gelijktijdig een tweede schijf kan uitvallen. Als de wederopbouw langer duurt, is de kans groter dat er gegevens verloren gaan.
Ceph herstelt de gegevens die verloren zijn gegaan op de defecte schijf met behulp van alle andere gezonde schijven in de cluster. Ceph zal alleen de gegevens die op de defecte schijf zijn opgeslagen opnieuw opbouwen/herstellen. Als er meer gezonde schijven zijn, zal de hersteltijd korter zijn.
- Configuratie Ceph CRUSH Kaart & Regel