分散式儲存
您可以使用 Ceph 來建構一個伺服器叢集,以實現高可用性的資料儲存。資料的副本(replications)或糾刪碼(erasure code)區塊會分散式地儲存在屬於不同預定義故障域的裝置中。當多個裝置、伺服器節點、機櫃或站點同時發生故障時,Ceph 仍能維持其資料服務,且不會遺失任何資料。
Ceph 軟體定義儲存
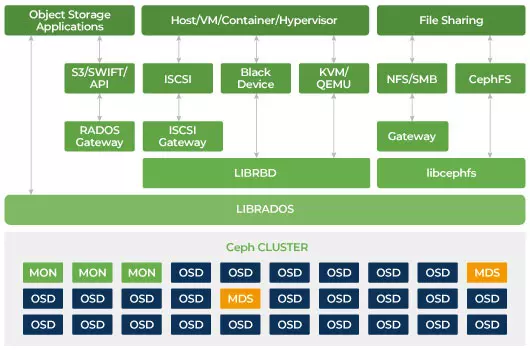
客戶端透過 Ceph 的分散式儲存演算法 CRUSH,直接與所有儲存裝置來進行讀寫。因為這種設計,Ceph 消除了傳統主機匯流排配接器 (HBA) 上的瓶頸,傳統 HBA 限制了儲存系統的可擴展性。Ceph 能將容量與效能近乎線性地擴展至 Exabyte(EB)等級。
Ceph 的設計宗旨是可擴展且沒有單點故障。在 Ceph 叢集中,Monitor(MON)、Object Storage Daemon(OSD)與 Metadata Server(MDS)是三個關鍵的守護行程(Linux 程序)。一般而言,Ceph 叢集會部署三個或以上的 MON 節點以提供備援。MON 維護叢集地圖(cluster maps)的主副本,使 Ceph 用戶端得以直接與 OSD 與 MDS 進行通訊;這些對應屬於關鍵的叢集狀態,供各 Ceph 守護行程彼此協調之用。MON 也負責管理守護行程與用戶端之間的身份驗證。採用奇數個 MON,透過仲裁 (quorum) 機制維持叢集地圖一致性,避免MON成為單一故障點,並確保其共識有效。OSD 是 Ceph 的物件儲存守護程序;負責儲存資料、處理資料複寫、恢復與再平衡,並透過檢查其他 OSD 的心跳(heartbeat)向 MON 提供監控資訊。每台儲存伺服器會運行一個或多個 OSD(通常每個儲存裝置對應一個 OSD)。為了冗餘與高可用性,通常至少需要 3 個 OSD。MDS 守護程序管理 Ceph 檔案系統(CephFS)上檔案的中繼資料,並協調對共享的 Ceph 儲存叢集的存取。可同時部屬多個 MDS 以提供冗餘並平衡負載。只有在需要使用共享檔案系統時,才需要部署一個或多個 MDS。
Ceph 是一種可擴展的儲存
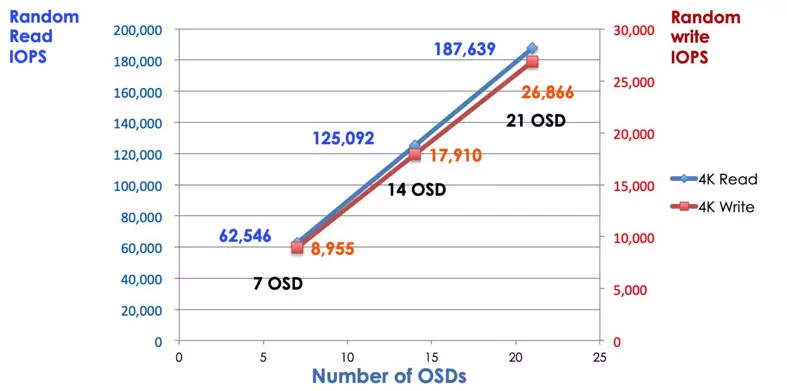
在傳統的儲存系統中,客戶端會與一個集中化的元件(例如 HBA 或閘道器)進行通訊,該元件是通往複雜子系統的單一進入點。集中式控制器不僅限制了效能和擴展性,也同時帶來了單點故障的隱憂。如果該集中式元件故障,整個系統也會隨之癱瘓。Ceph 客戶端會從 MON 獲取最新的叢集地圖 (cluster map),並使用 CRUSH 演算法來計算出要與叢集中哪個 OSD 進行通訊。這個演算法讓客戶端能夠直接與 Ceph OSD 互動,而無需經過集中式控制器。CRUSH 演算法消除了單一路徑的限制,從而解決了可擴展性的瓶頸問題。Ceph OSD 叢集為客戶端提供一個共享儲存池。當您需要更多容量或更高的效能時,可以透過新增 OSD 來擴展 (scale out) 該儲存池。Ceph 叢集的效能與 OSD 數量呈線性正比。下圖顯示了,當我們增加 OSD 數量時,讀寫 IOPS 也隨之增加。
傳統的磁碟陣列使用 RAID 控制器來保護資料,避免磁碟故障造成資料遺失。在 RAID 技術被發明時,硬碟的容量大約是 20MB。如今,磁碟容量已高達 16TB。當 RAID 陣列中的一顆磁碟機故障時,重建一顆故障磁碟可能需要一週。當 RAID 控制器正在重建該故障磁碟時,第二顆磁碟也可能同時發生故障。重建時間越長,資料遺失的機率就越高。
Ceph 會由叢集中其他所有健康的磁碟共同參與重建,將因故障磁碟而遺失的資料復原。Ceph 只會重建/修復原先存放在該故障磁碟上的資料;健康磁碟越多,復原所需時間就越短。
- 設定 Ceph CRUSH Map 與 Rule