
높은 데이터 가용성 및 내구성
Ceph 객체 저장소는 복제 및 고급 소거 코딩을 통해 데이터 가용성을 달성하며, 데이터는 패리티 정보와 결합된 후 샤드로 나뉘어 저장 풀에 분산됩니다.
저장 장치가 실패할 경우, 데이터 복구에 필요한 샤드의 하위 집합만 필요하며, 재구축 시간이나 성능 저하가 없고, 실패한 저장 장치는 편리할 때 교체할 수 있습니다.
Ceph는 널리 분산된 데이터와 미디어에 기록된 데이터를 지속적으로 검증하는 데이터 스크러빙 기술을 결합하여 15개의 9의 데이터 내구성을 달성할 수 있게 합니다.
데이터 복제, 소거 코딩 및 스크러빙
객체 복제
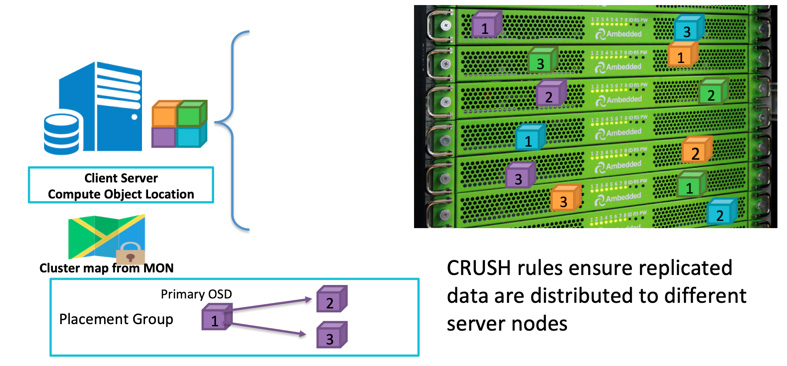
클라이언트가 데이터를 작성할 때, 객체 ID와 풀 이름을 사용하여 어떤 OSD에 작성해야 할지 계산합니다. 클라이언트가 데이터를 OSD에 작성한 후, OSD는 데이터를 하나 이상의 OSD로 복사합니다. 여러 개의 OSD가 동시에 실패하는 경우에도 데이터가 살아남을 수 있도록 원하는 만큼의 복제를 구성할 수 있습니다. 복제는 디스크 어레이의 RAID-1과 유사하지만 데이터의 복사본을 더 많이 허용합니다. 규모가 커지면 단순한 RAID-1 복제만으로는 하드웨어 고장의 위험을 충분히 커버하지 못할 수 있습니다. 더 많은 복제본을 저장하는 유일한 단점은 저장 비용입니다.
Ceph 클라이언트는 CRUSH 알고리즘에 기반하여 데이터를 무작위로 OSD에 기록합니다.OSD 디스크 또는 노드가 실패하면, Ceph는 데이터를 재생성할 수 있습니다.
Ceph가 전체 장애 도메인의 하나 이상의 장애로 인한 데이터 손실을 방지하기 위해 다른 서버, 랙, 룸 또는 데이터 센터에 복제된 데이터를 저장하도록 장애 도메인을 정의할 수 있습니다.예를 들어, 5개의 랙에 15개의 스토리지 서버가 설치되어 있다면 (각 랙에 3개의 서버), 장애 도메인으로 replica three와 rack을 사용할 수 있습니다.ceph 클러스터 에 데이터를 쓰면 항상 5개 랙 중 3개에 3개의 복사본이 저장됩니다.데이터는 최대 2개의 랙이 고장나도 클라이언트 서비스의 품질을 저하시키지 않고 유지될 수 있습니다.CRUSH 규칙은 Ceph 스토리지 가 단일 장애 지점이 없도록 하는 핵심입니다.
이레이저 코딩
복제는 전반적인 성능이 가장 우수하지만, 저장 공간 효율성은 그리 높지 않습니다.특히 더 높은 수준의 중복성이 필요한 경우입니다.
높은 데이터 가용성을 위해 과거에 RAID-1의 대안으로 RAID-5 또는 RAID-6을 사용했습니다.패리티 RAID는 저장 공간 성능(주로 쓰기 성능)의 비용으로 많이 줄어든 저장 공간 오버헤드와 함께 중복성을 보장합니다.Ceph는 유사한 결과를 얻기 위해 erasure encoding을 사용합니다.당신의 저장 시스템이 커질수록, 한 개 또는 두 개의 디스크 또는 장애 도메인이 동시에 실패할 경우에 대해 자신감을 가질 수 없을 수 있습니다.이레이저 코드 알고리즘을 사용하면 공간 오버헤드가 적은 상태에서 더 높은 수준의 장애 내성을 구성할 수 있습니다.
이레이저 코딩은 원본 데이터를 K개의 데이터 청크로 나누고 추가적인 M개의 코딩 청크를 계산합니다.Ceph는 동시에 최대 M개의 장애 도메인이 실패해도 데이터를 복구할 수 있습니다.다른 장애 도메인에 있는 OSD에 저장된 총 K+M 청크입니다.

스크러빙
데이터 일관성과 정리를 유지하기 위해 Ceph OSD 데몬은 배치 그룹 내의 객체를 스크럽할 수 있습니다. 즉, Ceph OSD Daemons는 한 placement group의 객체 메타데이터를 다른 OSD에 저장된 placement group의 복제본과 비교할 수 있습니다. 스크럽 (보통 매일 수행)은 버그나 파일 시스템 오류를 잡아냅니다. Ceph OSD 데몬은 객체의 데이터를 비트 단위로 비교하여 더 깊은 스크럽을 수행합니다. 깊은 스크러빙(일반적으로 매주 수행)은 가벼운 스크러빙에서는 드라이브의 나쁜 섹터를 찾지 못했던 것을 발견합니다.
데이터 복구
Ceph의 데이터 배치 디자인으로 인해 데이터는 모든 건강한 OSD에 의해 복구됩니다. 데이터 재복구를 위해 예비 디스크가 필요하지 않습니다. 이로 인해 디스크 어레이와 비교하여 재복구 시간이 훨씬 짧아질 수 있습니다. 디스크 어레이는 손실된 데이터를 예비 디스크로 다시 구축해야 합니다.
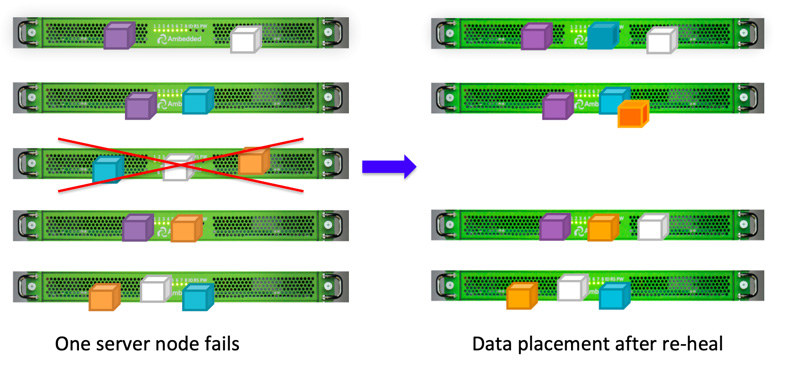
- CRUSH 맵 및 규칙 구성