분산 스토리지
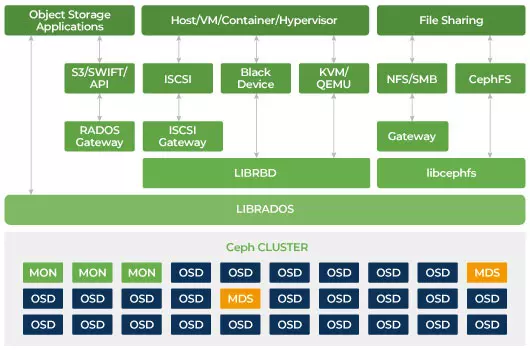
Ceph를 사용하여 고가용성으로 데이터를 저장하는 서버 클러스터를 구축할 수 있습니다. 데이터 복제 또는 손실 복구 코드 청크는 미리 정의된 다른 장애 도메인에 속하는 장치에 분산 저장됩니다. Ceph는 여러 장치, 서버 노드, 랙 또는 사이트가 동시에 고장나더라도 데이터를 손실하지 않고 데이터 서비스를 유지할 수 있습니다.
Ceph 소프트웨어 정의 스토리지
클라이언트는 Ceph의 분산 저장 알고리즘 CRUSH를 사용하여 모든 저장 장치와 직접 상호 작용하여 읽기 및 쓰기를 수행합니다. 이로 인해 저장 시스템의 확장성을 제한하는 전통적인 호스트 버스 어댑터 (HBA)에 대한 병목 현상이 제거됩니다. Ceph는 성능과 함께 용량을 엑사바이트 규모로 선형적으로 확장할 수 있습니다.
Ceph는 확장 가능하고 단일 장애점이 없도록 설계되었습니다. 모니터(MON), 객체 저장 데몬(OSD) 및 메타데이터 서버(MDS)는 Ceph 클러스터에서 세 가지 주요 데몬(Linux 프로세스)입니다. 일반적으로 Ceph 클러스터는 중복성을 위해 세 개 이상의 모니터 노드를 가지고 있습니다. 모니터는 클러스터 맵의 마스터 복사본을 유지하여 Ceph 클라이언트가 OSD와 MDS와 직접 통신할 수 있도록 합니다. 이 맵은 Ceph 데몬들이 서로 협력하기 위해 필요한 중요한 클러스터 상태입니다. 모니터는 데몬과 클라이언트 간의 인증을 관리하는 것도 책임집니다. 홀수 개의 모니터는 다수결을 사용하여 클러스터 맵을 유지합니다. 이 알고리즘은 모니터의 단일 장애점을 피하고 그들의 합의가 유효함을 보장합니다. OSD는 Ceph의 객체 저장 데몬입니다. 데이터를 저장하고, 데이터 복제, 복구, 리밸런싱을 처리하며, 다른 OSD 데몬의 하트 비트를 확인하여 Ceph Monitors에 일부 모니터링 정보를 제공합니다. 모든 저장 서버는 하나 이상의 OSD 데몬을 실행하며, 각각의 저장 장치당 하나의 OSD 데몬이 실행됩니다. 일반적으로 3개 이상의 OSD가 필요하며, 이는 중복성과 고가용성을 위해 필요합니다. MDS 데몬은 Ceph 파일 시스템에 저장된 파일과 관련된 메타데이터를 관리하며 공유 Ceph 스토리지 클러스터에 대한 액세스를 조정합니다. 여러 개의 활성 MDS를 가질 수 있으며, 각 MDS의 부하를 분산시키고 중복성을 확보할 수 있습니다. 공유 파일 시스템을 사용하려는 경우에만 하나 이상의 메타데이터 서버(MDS)가 필요합니다.
Ceph는 확장 가능한 저장소입니다.
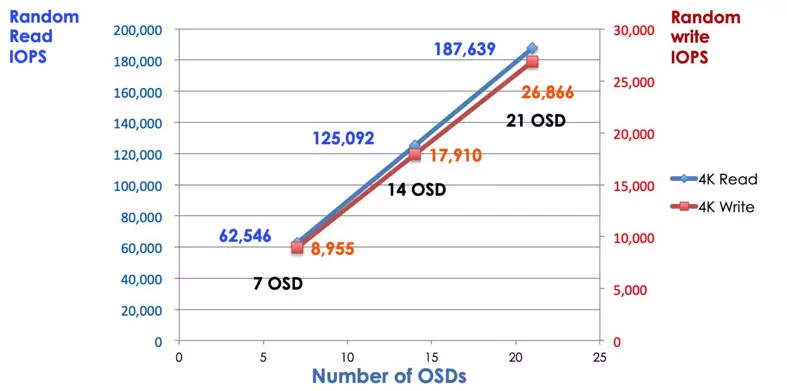
전통적인 저장 시스템에서는 클라이언트가 중앙 집중식 구성 요소(예: 호스트 버스 어댑터 또는 게이트웨이)와 대화하며, 이는 복잡한 하위 시스템의 단일 진입점입니다. 중앙 집중식 컨트롤러는 성능과 확장성에 제한을 가하며, 단일 장애 지점을 도입합니다. 중앙 집중식 구성 요소가 다운되면 전체 시스템도 다운됩니다. Ceph 클라이언트는 모니터에서 최신 클러스터 맵을 가져와 클러스터 내의 어떤 OSD를 사용할지 CRUSH 알고리즘을 사용하여 계산합니다. 이 알고리즘은 클라이언트가 중앙 집중식 컨트롤러를 거치지 않고 Ceph OSD와 직접 상호 작용할 수 있게 합니다. CRUSH 알고리즘은 확장성의 제한을 초래하는 단일 경로를 제거합니다. Ceph OSD 클러스터는 클라이언트에게 공유 스토리지 풀을 제공합니다. 용량이나 성능이 더 필요할 때는 새로운 OSD를 추가하여 풀을 확장할 수 있습니다. Ceph 클러스터의 성능은 OSD의 수에 선형적으로 비례합니다. 다음 그림은 OSD의 수를 증가시키면 읽기/쓰기 IOPS가 증가하는 것을 보여줍니다.
전통적인 디스크 어레이는 RAID 컨트롤러를 사용하여 디스크 장애로부터 데이터를 보호합니다. RAID 기술이 개발될 당시 하드 디스크 드라이브의 용량은 약 20MB였습니다. 오늘날 디스크 용량은 16TB와 같이 크다. RAID 그룹에서 실패한 디스크를 재구축하는 데 걸리는 시간은 일주일일 수 있습니다. RAID 컨트롤러가 실패한 드라이브를 재구성하는 동안, 동시에 두 번째 디스크가 고장날 수 있는 가능성이 있습니다. 재구축이 오래 걸릴 경우 데이터 손실 확률이 높아집니다.
Ceph는 클러스터의 다른 모든 건강한 드라이브를 통해 실패한 디스크에서 손실된 데이터를 복구합니다. Ceph는 실패한 드라이브에 저장된 데이터만 재구성/복구합니다. 건강한 디스크가 더 많을수록 복구 시간은 짧아집니다.
- Ceph CRUSH 맵 및 규칙 구성