Stockage distribué.
Vous pouvez utiliser Ceph pour construire un cluster de serveurs permettant de stocker des données en haute disponibilité. Les réplications de données ou les fragments de code d'effacement sont stockés de manière distribuée sur des dispositifs appartenant à différents domaines de défaillance prédéfinis. Ceph peut maintenir son service de données sans perte de données lorsque plusieurs dispositifs, nœuds de serveur, racks ou sites échouent simultanément.
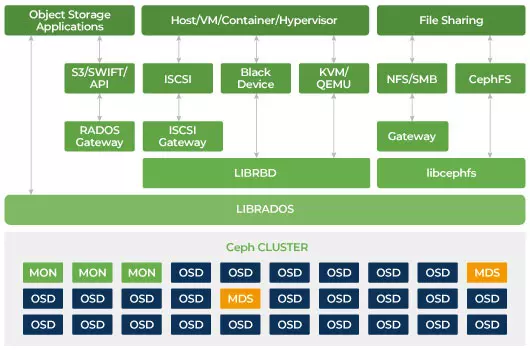
Stockage défini par logiciel Ceph.
Les clients interagissent directement avec tous les dispositifs de stockage pour lire et écrire en utilisant l'algorithme de stockage distribué CRUSH de Ceph. Grâce à cela, il élimine le goulot d'étranglement sur l'adaptateur de bus hôte (HBA) traditionnel, qui limite la scalabilité du système de stockage. Ceph peut étendre sa capacité de manière linéaire avec des performances à l'échelle de l'exaoctet.
Ceph est conçu pour être évolutif et ne pas avoir de point de défaillance unique. Les démons Monitor (MON), Object Storage Daemon (OSD) et Metadata Servers (MDS) sont les trois processus clés dans le cluster Ceph. Généralement, un cluster Ceph aura trois nœuds de surveillance ou plus pour la redondance. Les moniteurs maintiennent une copie maître des cartes de cluster, ce qui permet aux clients Ceph de communiquer directement avec les OSD et les MDS. Ces cartes sont l'état critique du cluster nécessaire aux démons Ceph pour se coordonner entre eux. Les moniteurs sont également responsables de la gestion de l'authentification entre les démons et les clients. Les nombres impairs de moniteurs maintiennent la carte du cluster en utilisant un quorum. Cet algorithme évite le point unique de défaillance sur le moniteur et garantit que leur consensus est valide. OSD est le démon de stockage d'objets pour Ceph. Il stocke des données, gère la réplication des données, la récupération, le rééquilibrage et fournit des informations de surveillance aux moniteurs Ceph en vérifiant les autres démons OSD pour le battement de cœur. Chaque serveur de stockage exécute un ou plusieurs démons OSD, un par périphérique de stockage. Au moins 3 OSD sont généralement nécessaires pour la redondance et la haute disponibilité. Le démon MDS gère les métadonnées liées aux fichiers stockés sur le système de fichiers Ceph et coordonne également l'accès au cluster de stockage Ceph partagé. Vous pouvez avoir plusieurs MDS actifs pour la redondance et équilibrer la charge de chaque MDS. Vous aurez besoin d'un ou plusieurs serveurs de métadonnées (MDS) uniquement lorsque vous souhaitez utiliser le système de fichiers partagé.
Ceph est un stockage évolutif
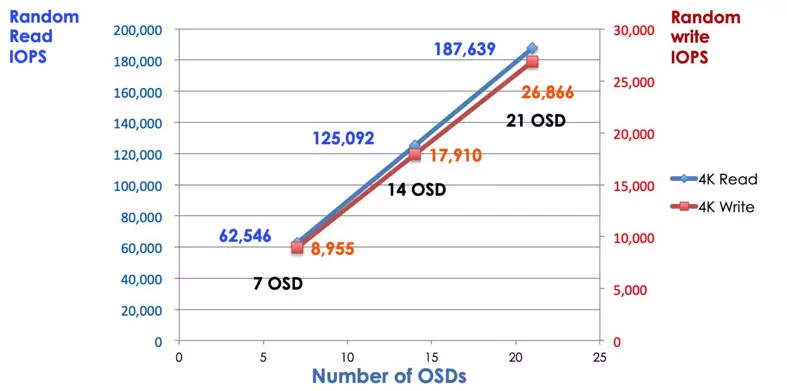
Dans un système de stockage traditionnel, les clients communiquent avec un composant centralisé (par exemple, un adaptateur de bus hôte ou une passerelle), qui est un point d'entrée unique vers un sous-système complexe. Le contrôleur centralisé impose une limite à la fois en termes de performance et de scalabilité, tout en introduisant un point de défaillance unique. Si le composant centralisé tombe en panne, tout le système tombe également. Les clients Ceph obtiennent la dernière carte du cluster à partir des moniteurs et utilisent l'algorithme CRUSH pour calculer quel OSD dans le cluster. Cet algorithme permet aux clients d'interagir directement avec Ceph OSD sans passer par un contrôleur centralisé. L'algorithme CRUSH élimine le chemin unique, ce qui entraîne une limitation de l'évolutivité. Le cluster Ceph OSD offre aux clients un pool de stockage partagé. Lorsque vous avez besoin de plus de capacité ou de performances, vous pouvez ajouter de nouveaux OSD pour étendre la piscine. Les performances d'un cluster Ceph sont proportionnelles au nombre d'OSD. L'image suivante montre l'augmentation des IOPS en lecture/écriture si nous augmentons le nombre de OSD.
Les disques durs traditionnels utilisent le contrôleur RAID pour protéger les données contre les défaillances des disques. La capacité d'un disque dur était d'environ 20 Mo lorsque la technologie RAID a été inventée. Aujourd'hui, la capacité du disque est aussi grande que 16 To. Le temps nécessaire pour reconstruire un disque défaillant dans le groupe RAID peut prendre une semaine. Pendant que le contrôleur RAID reconstruit le disque défaillant, il y a une chance qu'un deuxième disque puisse également échouer simultanément. Si la reconstruction prend plus de temps, la probabilité de perte de données est plus élevée.
Ceph récupère les données perdues sur le disque défaillant à partir de tous les autres disques sains du cluster. Ceph ne reconstruira/réparera que les données stockées sur le disque défaillant. S'il y a plus de disques sains, le temps de récupération sera plus court.
- Configurer la carte CRUSH Ceph et la règle