¿El almacenamiento Ceph Mars 400 admite recuperación ante desastres?
El almacenamiento Mars 400 ceph admite la recuperación ante desastres con 2 protocolos de almacenamiento.
1. Almacenamiento de bloques - Espejo asincrónico para RBD.
2. Almacenamiento de objetos: soporte activo-activo de RGW Multisite.
Los usuarios pueden utilizar el administrador UVS para configurar la recuperación ante desastres para RBD y S3.
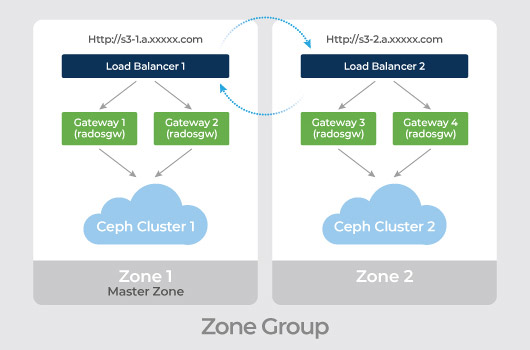
Mars 400 Ceph storage puede utilizar RGW multi-site activo-activo para diferentes ubicaciones geográficas, proporcionando un clúster de almacenamiento de alta disponibilidad.
El dispositivo Mars 400 ceph admite la instalación multisitio activo-activo para que los datos estén disponibles en múltiples ubicaciones diferentes.
Los usuarios pueden utilizar el administrador UVS en Mars 400 para ejecutar:
● Crear la puerta de enlace Rados para multisitio - Maestro.
● Crear la puerta de enlace Rados para multisitio - Secundario.
● Definir el grupo de zona con esas puertas de enlace Rados de multisitio.
● Obtener la clave de acceso del usuario.
● Obtener la clave secreta del usuario.
● Promover el sitio secundario como el sitio maestro cuando el sitio maestro falla.
Para más detalles, no dude en ponerse en contacto con el equipo de Ambedded o los socios de Ambedded.

Con la replicación asincrónica RBD de Ceph, el sitio secundario puede hacer una copia de seguridad de los datos del sitio principal para evitar pérdidas de datos.
Para el almacenamiento en bloque, el dispositivo Mars 400 ceph admite la replicación asincrónica RBD entre el sitio primario (A) y el sitio secundario (B).
● Si hay cambios o novedades en el sitio primario (A), la imagen y la instantánea RBD se replicarán en el sitio secundario (B).
● En caso de que los usuarios deseen restaurar a una fecha anterior, pueden revertir la imagen a la instantánea específica.
● Si el sitio primario (A) falla, el servidor cliente puede cambiar sus conexiones al sitio secundario (B) para continuar el servicio. Mars 400 también puede promover el sitio secundario (B) al sitio primario en caso de fallo del sitio primario original (A).
● Cuando el clúster A vuelva a la normalidad, los datos se pueden sincronizar con el sitio A para la recuperación.