
Yüksek Veri Erişilebilirliği ve Dayanıklılığı
Ceph nesne depolama, verilerin çoğaltılması ve gelişmiş silme kodlaması yoluyla veri erişilebilirliğini sağlar; bu süreçte veriler parite bilgisi ile birleştirilir ve ardından depolama havuzuna parçalanıp dağıtılır.
Bir depolama cihazı arızalandığında, verileri yeniden onarmak için yalnızca bir alt küme parçaya ihtiyaç vardır, yeniden inşa süresi veya performans düşüklüğü yoktur ve arızalı depolama cihazları uygun olduğunda değiştirilebilir.
Ceph, geniş dağıtılmış verileri ve sürekli olarak medya üzerine yazılan verileri doğrulayan veri temizleme teknolojisini birleştirerek, 15 dokuzluk veri dayanıklılığına ulaşmanızı sağlar.
Veri Çoğaltma, Silme Kodlama & Temizleme
Nesne Yedekleme
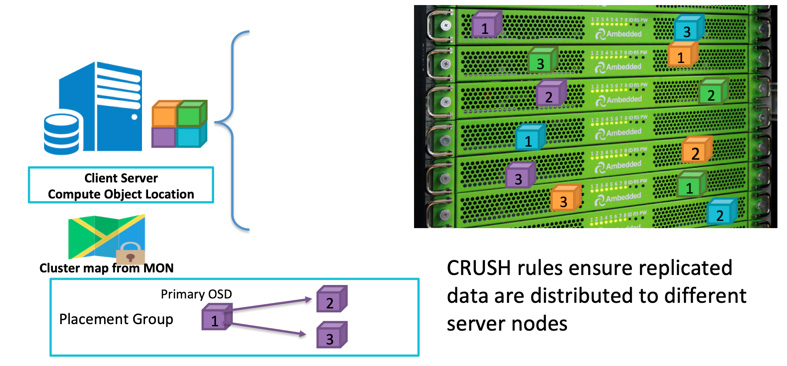
Bir istemci veri yazacağında, nesne kimliği ve havuz adını kullanarak hangi OSD'ye yazacağını hesaplar. Müşteri verileri OSD'ye yazdıktan sonra, OSD verileri bir veya daha fazla OSD'ye kopyalar. Aynı anda birden fazla OSD başarısız olursa verinin hayatta kalabilmesi için istediğiniz kadar replikasyon yapılandırabilirsiniz. Replikasyon, disk dizisi RAID-1'e benzer ancak daha fazla veri kopyasına izin verir. Çünkü ölçeklendirildiğinde, basit bir RAID-1 replikasyonu artık donanım arızası riskini yeterince kapsamayabilir. Daha fazla replika saklamanın tek dezavantajı depolama maliyetidir.
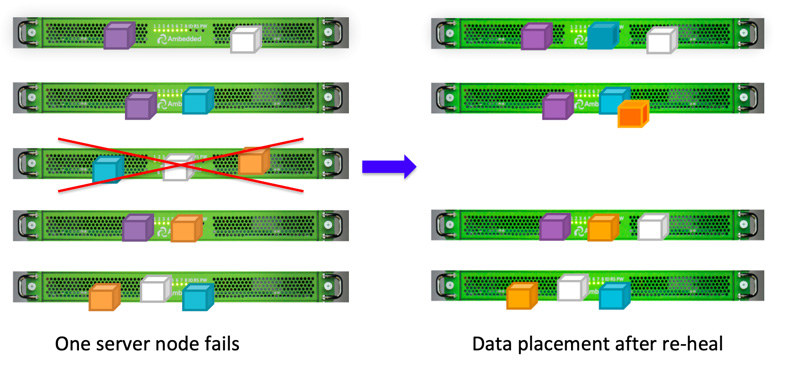
Ceph istemcileri, CRUSH algoritması'na göre rastgele OSDs'lere veri yazar.OSD diski veya düğümü başarısız olursa, Ceph sağlıklı OSD'lerde saklanan diğer çoğaltmalardan verileri yeniden iyileştirebilir.
Ceph'in, tüm başarısızlık alanının bir veya daha fazla arızası nedeniyle veri kaybını önlemek için, çoğaltılmış verileri farklı sunucularda, raflarda, odalarda veya veri merkezlerinde depolamasını sağlamak için başarısızlık alanını tanımlayabilirsiniz.Örneğin, 5 raf içinde (her bir rafda 3 sunucu olmak üzere) kurulu 15 depolama sunucusuna sahipseniz, başarısızlık alanı olarak üç kopya ve raf kullanabilirsiniz.Ceph kümesine veri yazma işlemi her zaman beş rafın üçünde üç kopya olarak saklanır.Veri, müşteri hizmetini bozmadan herhangi 2 raf arızalandığında bile sağ kalabilir.CRUSH kuralı, Ceph Depolama sisteminin tek bir arıza noktası olmamasını sağlamanın anahtarıdır.
Silme Kodlama
Replikasyon en iyi genel performansı sunar, ancak depolama alanı verimli değildir.Özellikle daha yüksek bir yedeklilik derecesine ihtiyacınız varsa.
Yüksek veri erişilebilirliğine sahip olmak için geçmişte RAID-1'in bir alternatifi olarak RAID-5 veya RAID-6 kullandık.Parity RAID, depolama performansının (çoğunlukla yazma performansının) maliyetine karşılık daha az depolama gereksinimiyle yedeklilik sağlar.Ceph, benzer bir sonuç elde etmek için silme kodlamasını kullanır.Depolama sisteminizin ölçeği büyüdüğünde, aynı anda sadece bir veya iki disk veya hata alanının başarısız olmasına izin vermekle kendinizi güvensiz hissedebilirsiniz.Silme kodu algoritması, daha yüksek bir yedeklilik düzeyi yapılandırmanızı sağlar, ancak daha az alan kullanır.
Silme kodlaması, orijinal veriyi K veri parçasına böler ve hesaplanan ek M kodlama parçası oluşturur.Ceph, aynı anda en fazla M hata alanında başarısızlık durumunda verileri kurtarabilir.Farklı arıza alanlarında bulunan OSD'lerde depolanan toplam K+M parçaları.

Temizleme
Veri tutarlılığı ve temizliğini sağlamanın bir parçası olarak, Ceph OSD Daemonları yerleştirme grupları içinde nesneleri temizleyebilir. Yani, Ceph OSD Daemonları bir yerleştirme grubundaki nesne meta verilerini diğer OSD'lerde depolanan yerleştirme gruplarındaki replikalarıyla karşılaştırabilir. Temizlik (genellikle günlük olarak yapılır), hataları veya dosya sistemi hatalarını yakalar. Ceph OSD Daemons, nesnelerdeki verileri bit bit karşılaştırarak daha derin bir tarama yaparlar. Hafif temizlikte fark edilmeyen bir sürücüdeki kötü sektörleri bulan derin temizlik (genellikle haftalık olarak yapılır).
Veri Kurtarma
Ceph'in veri yerleştirme tasarımı nedeniyle veri, tüm sağlıklı OSD'ler tarafından iyileştirilir. Veri yeniden iyileştirme için yedek disk gerekmez. Bu, kaybedilen veriyi yedek diske yeniden oluşturması gereken disk dizisine kıyasla iyileştirme süresini çok daha kısa hale getirebilir.
- CRUSH haritası ve kurallarını yapılandır