
ความพร้อมใช้งานและความทนทานของข้อมูลสูง
Ceph object storage บรรลุความพร้อมใช้งานของข้อมูลผ่านการทำซ้ำและการเข้ารหัสการลบขั้นสูง โดยที่ข้อมูลจะถูกรวมกับข้อมูลพาริตี้และจากนั้นจะแบ่งเป็นชิ้นส่วนและกระจายไปทั่วพูลเก็บข้อมูล.
เมื่ออุปกรณ์เก็บข้อมูลล้มเหลว จะต้องใช้เพียงชุดย่อยของชิ้นส่วนเพื่อฟื้นฟูข้อมูล ไม่มีเวลาสร้างใหม่หรือประสิทธิภาพที่ลดลง และอุปกรณ์เก็บข้อมูลที่ล้มเหลวสามารถเปลี่ยนได้เมื่อสะดวก.
Ceph รวมข้อมูลที่กระจายอย่างกว้างขวางและเทคโนโลยีการตรวจสอบข้อมูลที่ตรวจสอบความถูกต้องของข้อมูลที่เขียนลงบนสื่ออย่างต่อเนื่อง ซึ่งสามารถช่วยให้คุณบรรลุความทนทานของข้อมูลถึง 15 nines.
การทำซ้ำข้อมูล, การเข้ารหัสการลบ & การตรวจสอบ
การทำซ้ำวัตถุ
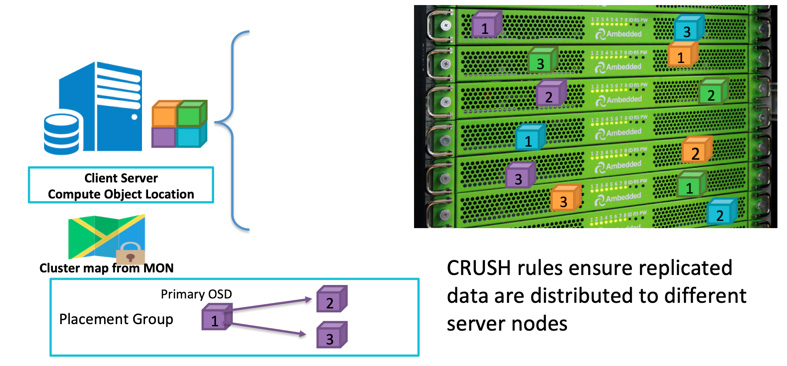
เมื่อลูกค้าต้องการเขียนข้อมูล จะใช้รหัสวัตถุและชื่อพูลเพื่อคำนวณว่าจะเขียนลงใน OSD ใด หลังจากที่ลูกค้าเขียนข้อมูลไปยัง OSD แล้ว OSD จะทำการคัดลอกข้อมูลไปยัง OSD หนึ่งหรือมากกว่าหนึ่ง คุณสามารถกำหนดค่าการทำซ้ำได้มากเท่าที่คุณต้องการเพื่อให้ข้อมูลสามารถรอดตัวได้ในกรณีที่ OSD หลายตัวล้มเหลวพร้อมกัน การทำซ้ำคล้ายกับ RAID-1 ของอาร์เรย์ดิสก์ แต่อนุญาตให้มีสำเนาข้อมูลมากกว่า เพราะในขอบเขตของมาตราส่วนใหญ่ การทำ RAID-1 ซึ่งเป็นการทำสำเนาข้อมูลอาจไม่เพียงพอในการครอบคลุมความเสี่ยงจากการล้มเหลวของฮาร์ดแวร์อีกต่อไป ข้อเสียเดียวของการเก็บข้อมูลสำเนามากขึ้นคือค่าใช้จ่ายในการจัดเก็บข้อมูล
ลูกค้า Ceph เขียนข้อมูลไปยัง OSD โดยสุ่มตามอัลกอริทึม CRUSH.หาก OSD ดิสก์หรือโหนดล้มเหลว Ceph สามารถ รักษาข้อมูลใหม่ จากการทำซ้ำที่เก็บไว้ใน OSD ที่ปลอดภัย
คุณสามารถ กำหนดโดเมนที่ล้มเหลว เพื่อให้ Ceph เก็บข้อมูลที่มีการทำซ้ำในเซิร์ฟเวอร์ แร็ก ห้อง หรือศูนย์ข้อมูลที่แตกต่างกัน เพื่อป้องกันการสูญเสียข้อมูลที่เกิดจากความล้มเหลวของโดเมนที่ล้มเหลวทั้งหมดหรือมากกว่านั้นตัวอย่างเช่น หากคุณมีเซิร์ฟเวอร์จัดเก็บข้อมูล 15 เครื่องติดตั้งใน 5 แผง (3 เซิร์ฟเวอร์ในแต่ละแผง) คุณสามารถใช้ replica สามและแผงเป็นโดเมนที่เกิดความล้มเหลวการเขียนข้อมูลไปยัง Ceph cluster จะมีการเก็บสำเนาสามตำแหน่งในราวกล่องทั้งห้าเสมอข้อมูลสามารถรอดตามจำนวนราวกับ 2 แท่นที่ล้มเหลวโดยไม่ทำให้บริการลูกค้าเสียคุณภาพกฎ CRUSH คือกุญแจสำคัญในการทำให้ Ceph storage มีไม่มีจุดเดียวที่จะล้มเหลว.
การเขียนข้อมูลแบบลบล้าง
การทำซ้ำให้ประสิทธิภาพที่ดีที่สุดโดยรวม แต่มันไม่เป็นประสิทธิภาพในการจัดเก็บพื้นที่เก็บข้อมูลมากนักโดยเฉพาะอย่างยิ่งหากคุณต้องการระดับความซ้ำซ้อนที่สูงขึ้น.
การมีความพร้อมข้อมูลสูงเป็นเหตุผลที่เราใช้ RAID-5 หรือ RAID-6 ในอดีตเป็นทางเลือกแทน RAID-1.RAID แบบ Parity ให้ความมั่นคงด้วยการใช้พื้นที่จัดเก็บน้อยกว่ามาก แต่มีผลต่อประสิทธิภาพการจัดเก็บข้อมูล (โดยเฉพาะประสิทธิภาพการเขียน) ที่ต้องเสียCeph ใช้การเข้ารหัสแบบการลบข้อมูลเพื่อให้ได้ผลลัพธ์ที่คล้ายกันเมื่อขนาดของระบบจัดเก็บข้อมูลของคุณมีขนาดใหญ่ขึ้น คุณอาจรู้สึกไม่มั่นใจในการอนุญาตให้ดิสก์หรือโดเมนที่เกิดความล้มเหลวมีจำนวนเพียงหนึ่งหรือสองตัวล้มเหลวในเวลาเดียวกันอัลกอริทึมการลบข้อมูลช่วยให้คุณสามารถกำหนดค่าระดับความซ้ำซ้อนที่สูงขึ้น แต่มีพื้นที่เกินน้อยลง
การเข้ารหัสข้อมูลชิ้นเดิมเป็นชิ้นเล็กๆ K และคำนวณชิ้นเพิ่มเติม MCeph สามารถกู้คืนข้อมูลได้สูงสุด M โดเมนที่ล้มเหลวในขณะเดียวกันจำนวนรวมของ K+M ของชิ้นส่วนถูกเก็บไว้ใน OSDs ซึ่งอยู่ในโดเมนการล้มเหลวที่แตกต่างกัน

การล้าง
เพื่อรักษาความสอดคล้องและความสะอาดของข้อมูล Ceph OSD Daemons สามารถทำการตรวจสอบวัตถุภายในกลุ่มการจัดวางได้ นั่นคือ Ceph OSD Daemons สามารถเปรียบเทียบข้อมูลเมตาดาต้าของวัตถุในกลุ่มการวางได้กับสำเนาของวัตถุในกลุ่มการวางที่เก็บไว้บน OSD อื่น การล้าง (ที่ทำทุกวันโดยทั่วไป) ช่วยตรวจจับข้อผิดพลาดหรือข้อผิดพลาดในระบบไฟล์ เซฟ OSD Daemons ยังทำการตรวจสอบลึกลงไปโดยการเปรียบเทียบข้อมูลในวัตถุทีละบิต การล้างทำความสะอาดลึก (ที่ทำเป็นประจำสัปดาห์) จะค้นหาเซ็กเตอร์ที่เสียหายบนไดรฟ์ที่ไม่เห็นได้ในการล้างแสงเบา
การฟื้นฟูข้อมูล
เนื่องจากการออกแบบการวางข้อมูลของ Ceph ข้อมูลจะถูกฟื้นฟูโดย OSDs ที่สมบูรณ์ทั้งหมด ไม่จำเป็นต้องมีดิสก์สำรองสำหรับการฟื้นฟูข้อมูล สิ่งนี้ทำให้เวลาในการฟื้นฟูสั้นลงมากเมื่อเปรียบเทียบกับอาร์เรย์ดิสก์ที่ต้องสร้างข้อมูลที่สูญหายไปใหม่บนดิสก์สำรอง
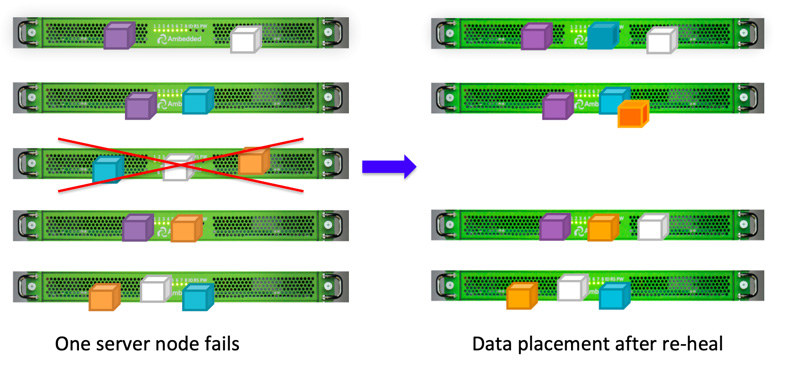
- กำหนดค่าแผนที่ CRUSH และกฎ