การจัดเก็บแบบกระจาย
คุณสามารถใช้ Ceph เพื่อสร้างกลุ่มเซิร์ฟเวอร์สำหรับเก็บข้อมูลในโหมดความพร้อมใช้งานสูง การทำซ้ำข้อมูลหรือการแบ่งข้อมูลเป็นชิ้นย่อยดูแลโดยการจัดเก็บในอุปกรณ์ที่อยู่ในโดเมนการล้มเหลวที่กำหนดไว้ล่วงหน้า Ceph สามารถรักษาการให้บริการข้อมูลได้โดยไม่สูญเสียข้อมูลเมื่ออุปกรณ์หลายตัว โหนดเซิร์ฟเวอร์ แร็กหรือเว็บไซต์ล้มเหลวพร้อมกัน
พื้นที่เก็บข้อมูลที่กำหนดโดยซอฟต์แวร์ Ceph
ลูกค้าสามารถติดต่อกับอุปกรณ์จัดเก็บข้อมูลทั้งหมดโดยตรงเพื่ออ่านและเขียนโดยใช้อัลกอริทึมการจัดเก็บแบบกระจายของ Ceph ทำให้เกิดการกำจัด bottleneck บน Host Bus Adaptor (HBA) ที่เป็นแบบดั้งเดิมซึ่งจำกัดความสามารถในการขยายขนาดของระบบจัดเก็บข้อมูล Ceph สามารถขยายความจุของระบบได้เป็นเส้นตรงพร้อมกับประสิทธิภาพไปจนถึงมาตราเอกซะไบต์
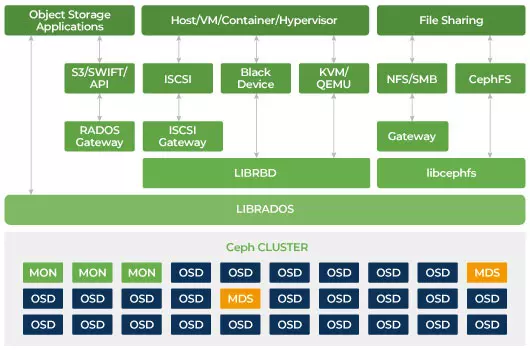
Ceph ถูกออกแบบให้สามารถขยายขนาดได้และไม่มีจุดล้มเหลวเดียว Monitor (MON), Object Storage Daemon (OSD), และ Metadata Servers (MDS) เป็นสามตัวประหยัดสำคัญใน Ceph cluster. โดยปกติแล้ว คลัสเตอร์ Ceph จะมีโหนดตรวจสอบสามหรือมากกว่าสำหรับความเสถียร ผู้ควบคุมรักษาสำเนาหลักของแผนที่คลัสเตอร์ซึ่งอนุญาตให้ไคลเอนต์ Ceph สื่อสารกับ OSD และ MDS โดยตรง แผนที่เหล่านี้เป็นสถานะคลัสเตอร์ที่สำคัญที่จำเป็นสำหรับเดมอน Ceph เพื่อประสานงานกัน ผู้ตรวจสอบยังรับผิดชอบในการจัดการการตรวจสอบความถูกต้องระหว่างเดมอนและไคลเอ็นต์ จำนวนจอคี่จะรักษาแผนที่ของกลุ่มโดยใช้ควอรัม อัลกอริทึมนี้หลีกเลี่ยงจุดที่เสียหายเดียวในการตรวจสอบและรับรองว่าความเห็นของพวกเขาถูกต้อง OSD เป็นเซิร์ฟเวอร์เก็บข้อมูลวัตถุสำหรับ Ceph. มันจัดเก็บข้อมูล จัดการการทำซ้ำข้อมูล การกู้คืนข้อมูล การทำสมดุลและให้ข้อมูลการตรวจสอบการติดตามให้กับ Ceph Monitors โดยการตรวจสอบ OSD Daemons อื่น ๆ เพื่อตรวจสอบการเต้นของหัวใจ ทุกเซิร์ฟเวอร์จัดเก็บข้อมูลทำงานด้วย OSD หนึ่งหรือหลายตัว หนึ่งตัวต่ออุปกรณ์จัดเก็บข้อมูล ต้องการอย่างน้อย 3 OSDs เพื่อความทนทานและความพร้อมใช้งานสูง เดอะเดมอน MDS จัดการข้อมูลเกี่ยวกับไฟล์ที่เก็บบนระบบไฟล์ Ceph และยังประสานการเข้าถึงสู่กลุ่มจัดเก็บ Ceph ที่ใช้ร่วมกัน คุณสามารถมี MDS หลายตัวที่ใช้งานได้พร้อมกันเพื่อเพิ่มความเสถียรและปรับสมดุลของการโหลดของแต่ละ MDS คุณจะต้องใช้เซิร์ฟเวอร์ Metadata (MDS) หนึ่งหรือมากกว่าเมื่อคุณต้องการใช้ระบบไฟล์ที่ใช้ร่วมกัน
Ceph เป็นการจัดเก็บข้อมูลที่สามารถขยายขนาดได้
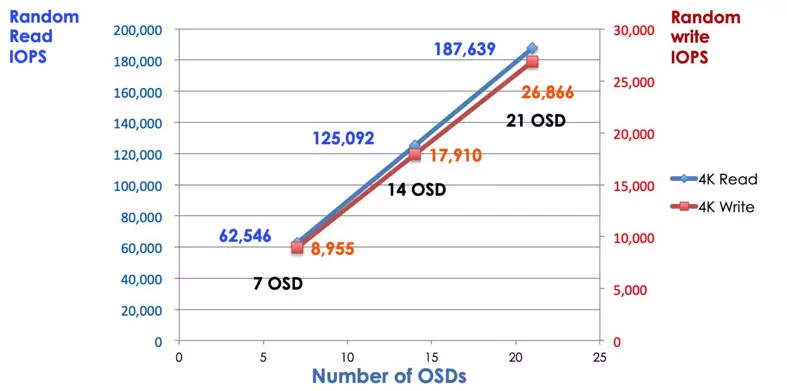
ในระบบจัดเก็บแบบดั้งเดิมลูกค้าพูดคุยกับส่วนประกอบที่ถูกจัดกลายเป็นจุดศูนย์กลาง (เช่น อะแดปเตอร์ของโฮสต์หรือเกตเวย์) ซึ่งเป็นจุดเข้าสู่ระบบย่อยที่ซับซ้อน ตัวควบคุมที่ถูกกลายเป็นจุดศูนย์กลางจำกัดการทำงานและความยืดหยุ่นพร้อมทั้งเป็นต้นเหตุของจุดล้มเหลวเดียว หากส่วนประกอบที่เป็นศูนย์กลางล้มเหลว ระบบทั้งหมดก็จะล้มเหลวด้วย ไคลเอ็นต์ Ceph จะได้รับแผนที่คลัสเตอร์ล่าสุดจากตัวควบคุมและใช้อัลกอริทึม CRUSH เพื่อคำนวณว่า OSD ใดในคลัสเตอร์ อัลกอริทึมนี้ช่วยให้ลูกค้าสามารถติดต่อกับ Ceph OSD โดยตรงโดยไม่ต้องผ่านคอนโทรลเลอร์ที่มีการควบคุมที่เซ็นทรัลไลฟ์ อัลกอริทึม CRUSH กำจัดเส้นทางเดียวซึ่งเป็นสาเหตุของข้อจำกัดในการขยายขนาด Ceph OSD คลัสเตอร์ให้ลูกค้าสระน้ำที่ใช้ร่วมกัน เมื่อคุณต้องการความจุหรือประสิทธิภาพเพิ่มเติม คุณสามารถเพิ่ม OSD ใหม่เพื่อขยายขนาดพูลได้ ประสิทธิภาพของกลุ่ม Ceph เป็นสัมพันธ์เชิงเส้นกับจำนวน OSD ภาพถ่ายต่อไปนี้แสดงให้เห็นถึงการเพิ่ม IOPS ในการอ่าน/เขียนเมื่อเราเพิ่มจำนวน OSD
อาร์เรย์ดิสก์แบบดั้งเดิมใช้คอนโทรลเลอร์ RAID เพื่อป้องกันข้อมูลจากการล้มเหลวของดิสก์ ความจุของฮาร์ดดิสก์ไดรฟ์ประมาณ 20MB เมื่อเทคโนโลยี RAID ถูกสร้างขึ้น วันนี้ความจุดิสก์มีขนาดใหญ่ถึง 16TB เวลาในการสร้างข้อมูลใหม่ในดิสก์ที่ล้มเหลวในกลุ่ม RAID อาจใช้เวลาสัปดาห์หนึ่ง ในขณะที่คอนโทรลเลอร์ RAID กำลังสร้างข้อมูลใหม่ในไดรฟ์ที่ล้มเหลว มีโอกาสที่ไดรฟ์ที่สองอาจล้มเหลวพร้อมกัน หากการสร้างใหม่ใช้เวลานานขึ้น โอกาสที่จะสูญเสียข้อมูลจะสูงขึ้น
Ceph กู้คืนข้อมูลที่สูญหายจากดิสก์ที่ล้มเหลวโดยใช้ดิสก์ที่ทำงานปกติทั้งหมดในคลัสเตอร์ Ceph จะทำการสร้าง/ซ่อมแซมข้อมูลที่เก็บอยู่ในดิสก์ที่ล้มเหลวเท่านั้น หากมีดิสก์ที่ทำงานปกติมากขึ้น เวลาที่ใช้ในการกู้คืนจะสั้นลง.
- กำหนดค่า Ceph CRUSH Map & กฎ